Tabular data: Before you use the data
In my previous blog, I promised to share with you more on goodtables, how they synergise with the data package. It's time to pay the debt!
Whether it be your own-generated data or someone else’s, the point of entry into the science-art of data analysis is one. You have heard of it. Yes, it is quality control checks. It saves you a lot of precious things: time, money, resources… The scope of my imagination within the space of time, the time of this writing, restricts me to a bimodal approach to validation, at least in the broad sense of it. These I would christen Intrinsic and Extrinsic validations. Let me expound. Data can be validated in and of itself (intrinsic) or by cross-referencing to a known standard (extrinsic). Validation is sometimes a repeating process that is performed at different stages of data handling, yet I consider the first-time-interaction validation to be most crucial. I guess a plethora of mechanisms/tools are out there for data validation, please leave a comment with your favourite tool. A common tool in the realm of bioinformatics is the md5sum in verifying the integrity of read files. But it is not our point of focus today, rather, I want to talk about goodtables, a Frictionless data (FD) tool for validating tabular data sets. As hinted by the name, you only want to work on/with tabular data in good condition; the tool highlights errors in your tabular dataset, with the precision of the exact location of your error. Again, the beautiful thing about FD tools is that they don’t discriminate on your preferences, it encompasses the Linux-based CLI, Python, GUI folks, among other languages. However, the capabilities may vary.
Validating tabular data with try.goodtables.io
The landing page for try.goodtables will look like Fig. 1 below. Note that Format and Encoding are set to automatic infer by default, but you may change them if necessary by toggling the drop-down for available options.
 Fig. 1: try.goodtables landing page.
Fig. 1: try.goodtables landing page.
Intrinsic Validation: Using only the file
The web app is very welcoming, you will be good to go almost immediately. In the first validation scenario, intrinsic, we will basically be checking the file itself for any structural errors: blank headers, missing-value, duplicate-rows etcetera. You will need to paste the URI (Universal Resource Identifier) link to your tabular data file into the source slot, alternatively, you can upload a file from your local filesystem. You can guess what would be next - click the Validate button and shortly wait for the magic. There are a number of other possible structural errors you can encounter, you will find an exhaustive list here. Be aware not to fall into the trap of source error; it will entangle you if you use the location link URL - Universal Resource Locator, rather than the URI.
Extrinsic Validation: Using the file and the schema
What is different about option two? In the extrinsic validation, we compare the data file to a schema we generate in the data package we earlier created. See my previous blog on creating a data package, if you have no idea of what a data package is. Summarily, a data package contains three things: metadata, data (in the form of path/URI link) and schema. The schema is extracted from the data package file and separately saved as a .json file. In Fig. 2 below, annexed from my datapackage, I have grey-highlighted the section of my data package that constitutes the schema file. The schema corresponds to this data file, the second resource in the data package.
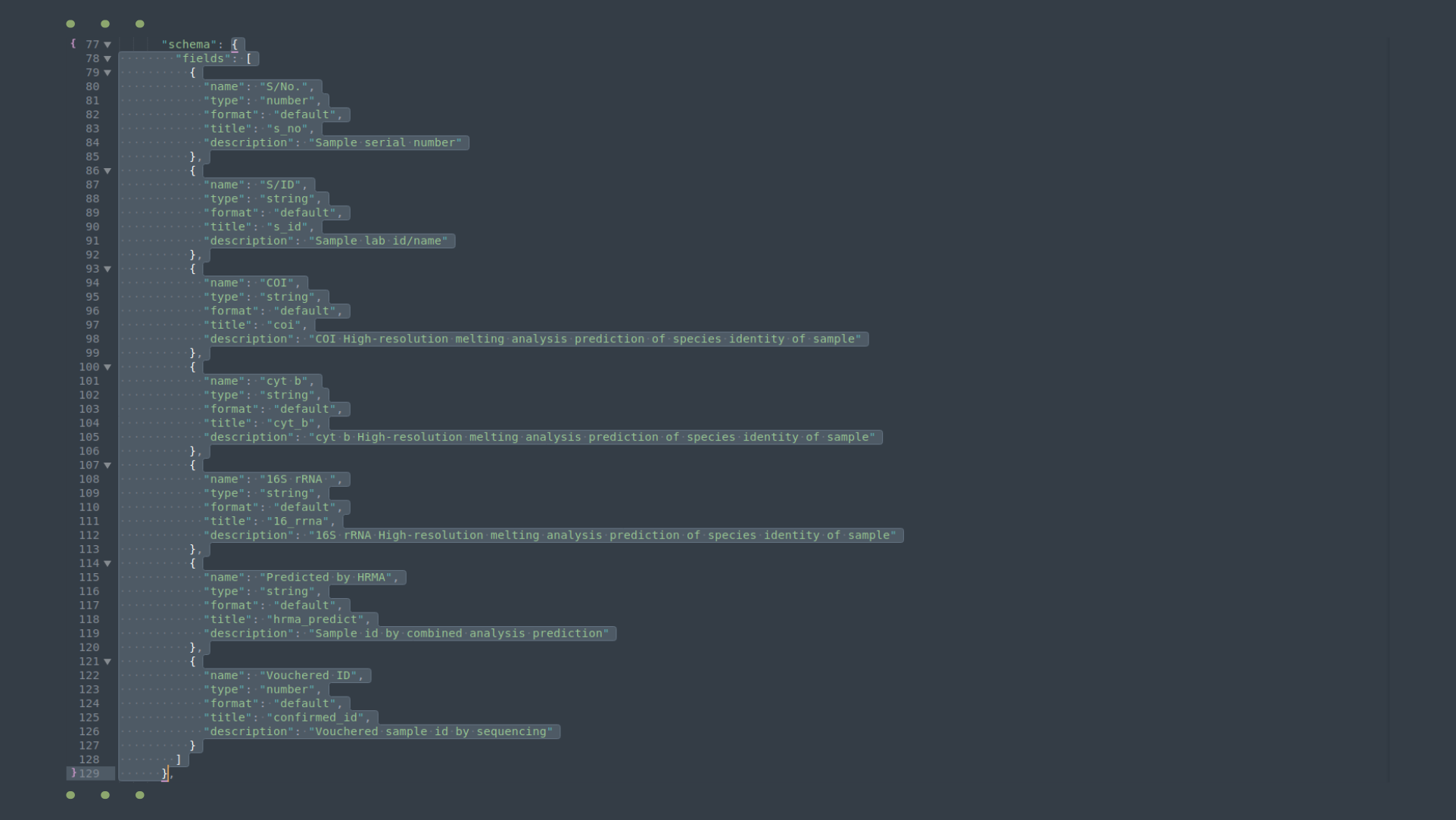 Fig. 2: The schema region of the data package selected between lines 77 and 129.
Fig. 2: The schema region of the data package selected between lines 77 and 129.
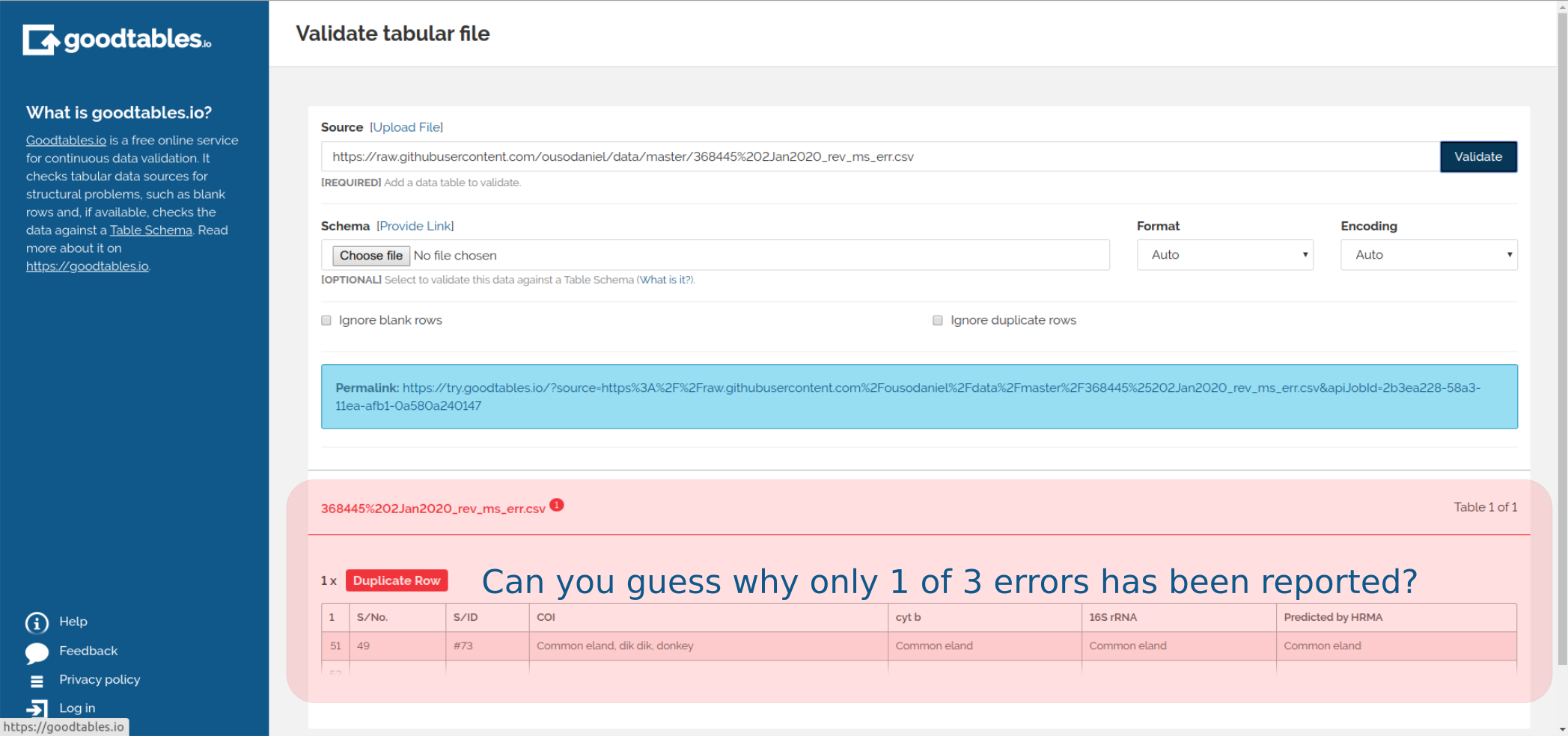 Fig. 3: Output showing the intrinsic validation of a data file with errors.
Fig. 3: Output showing the intrinsic validation of a data file with errors.
Ignore-blank-rows and Ignore-duplicate-rows, which you may toggle on or off depending on your preferences. Fig. 4 below shows the output of my with-schema validation, notice the other errors are now captured.
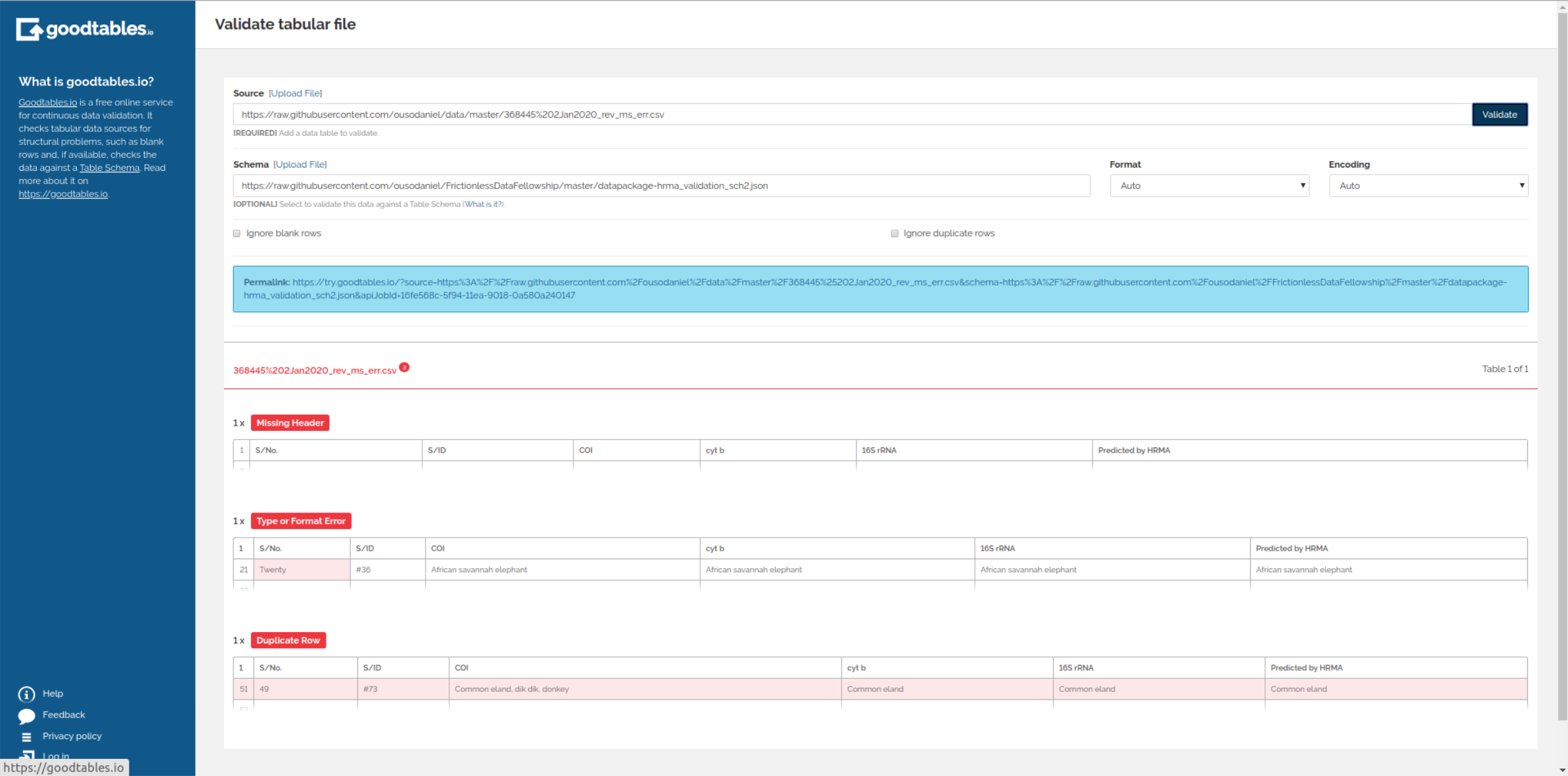 Fig. 4: Output showing the extrinsic validation of a data file with errors.
Fig. 4: Output showing the extrinsic validation of a data file with errors.
Other options
You may prefer to work with goodtables from the terminal or from inside a programming language, or perchance your data workflows are repetitive or long and complex, which then necessitates automation of the validation process. Fear not. The programmatic interfaces for goodtables exist, see earlier links for your preferred platform. For my case, the terminal and Python, the command pip install goodtables from the terminal will install the package. For detailed use in Terminal and Python, the Python Package Index has wonderful documentation.
Conclusion
Given my data, from which I had created a data package, is openly available; I managed to check for any changes I might have merged from a pull request or committed myself, without remembrance, or by a malicious intruder. Consequently, if I were to apply an analysis previously applied to the original data to my valid data, I would expect a reproduced result. While the first validation takes only one input, the second takes two input parameters, the data file and the schema file bring to fore the more salient errors. The input data file can take varied formats: CSV, JSON, XLS and similar formats; the schema must be a .json file. Although we only touched on the one-time validation in this blog, it is possible to set up a continuous validation on a number of online databases. This will be quite helpful in data workflows that involve continuous updating of the data. Moreover, with help from OKF, you can set up your own integration of goodtables to your custom database, if you don't use the officially supported data publishing plartforms.