¿Cómo empaquetamos datos y por qué es importante organizar la bolsa del supermercado?
Empaquetando datos sobre aborto desde OpenStreetMap Esta es una publicación para compartirles sobre el proceso y pasos para crear datapackages. ¿Qué es esto? Un datapackage es básicamente un empaquetado que agiliza la forma en que compartimos y replicamos los datos. Es como un contenedor de datos listo para ser transportado por la autopista del conocimiento (geeky, right).
¿Por qué queremos empaquetar estos datos? Porque desde el programa de fellows, queremos datasets que no tengan fricciones (frictionless data), es decir que puedan ser replicables, reutilizables y así aportar a mejores procesos en los cuáles se pueda aperturar y compartir conocimiento. Si revisan las guías de campo, pueden encontrar más información sobre el programa.
Los datapackages pueden contener los datos en CSV (comma separated values), los esquemas de datos en formato de json y los metadatos de tus… datos….
Mi datapackage responde a datos geoespaciales sobre centros (clínicas) de aborto en el mundo que se encuentran mapeados en OpenStreetMap. Lo que hice para conseguir estos datos fue muy sencillo, utilicé la API Overpass Turbo con esta consulta (gracias a la ayuda de las compañeras de Geochicas) que arrojó 101 nodos mapeados. En este punto es que empieza la validación y el empaquetado de los datos.
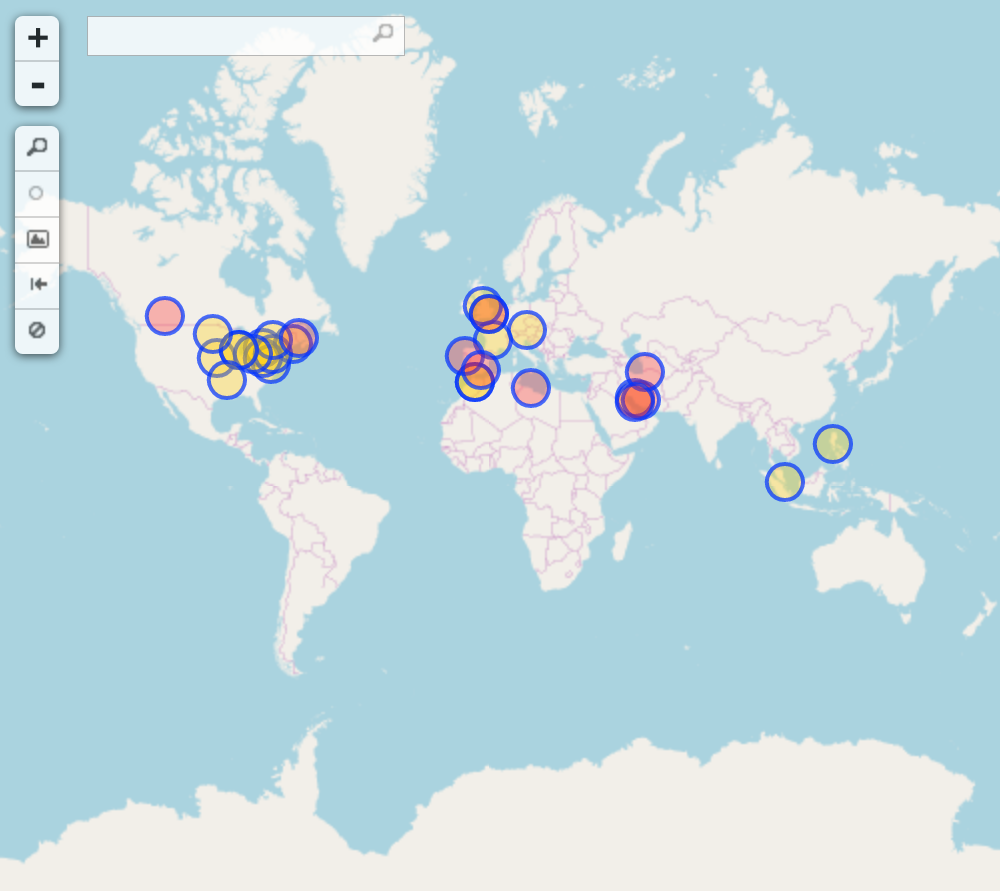
Ahora, ¿por qué decidí utilizar este dataset? Porque mi investigación doctoral y el trabajo que realizamos desde el colectivo de Geochicas, busca enlazar el análisis espacial entre el tipo de objetos mapeados, el género de la persona que mapea dichos puntos y también las representaciones de género que existen en el espacio.
Los datos que resultaron de la búsqueda realizada a través de Overpass Turbo, son descargables desde la misma API, en formato: GeoJson, GPX, y KML. También se pueden descargar las visualizaciones del mapa y el texto de la búsqueda.
La consulta es:
/*
This has been generated by the overpass-turbo wizard.
The original search was:
“healthcare:speciality=abortion or name like abortion”
*/
[out:json][timeout:900];
// gather results
(
// query part for: “"healthcare:speciality"=abortion”
node["healthcare:speciality"="abortion"]({{bbox}});
way["healthcare:speciality"="abortion"]({{bbox}});
relation["healthcare:speciality"="abortion"]({{bbox}});
// query part for: “name~abortion”
node["name"~"^abortion*"]({{bbox}});
way["name"~"^abortion*"]({{bbox}});
relation["name"~"^abortion*"]({{bbox}});
);
// print results
out body;
>;
out skel qt;
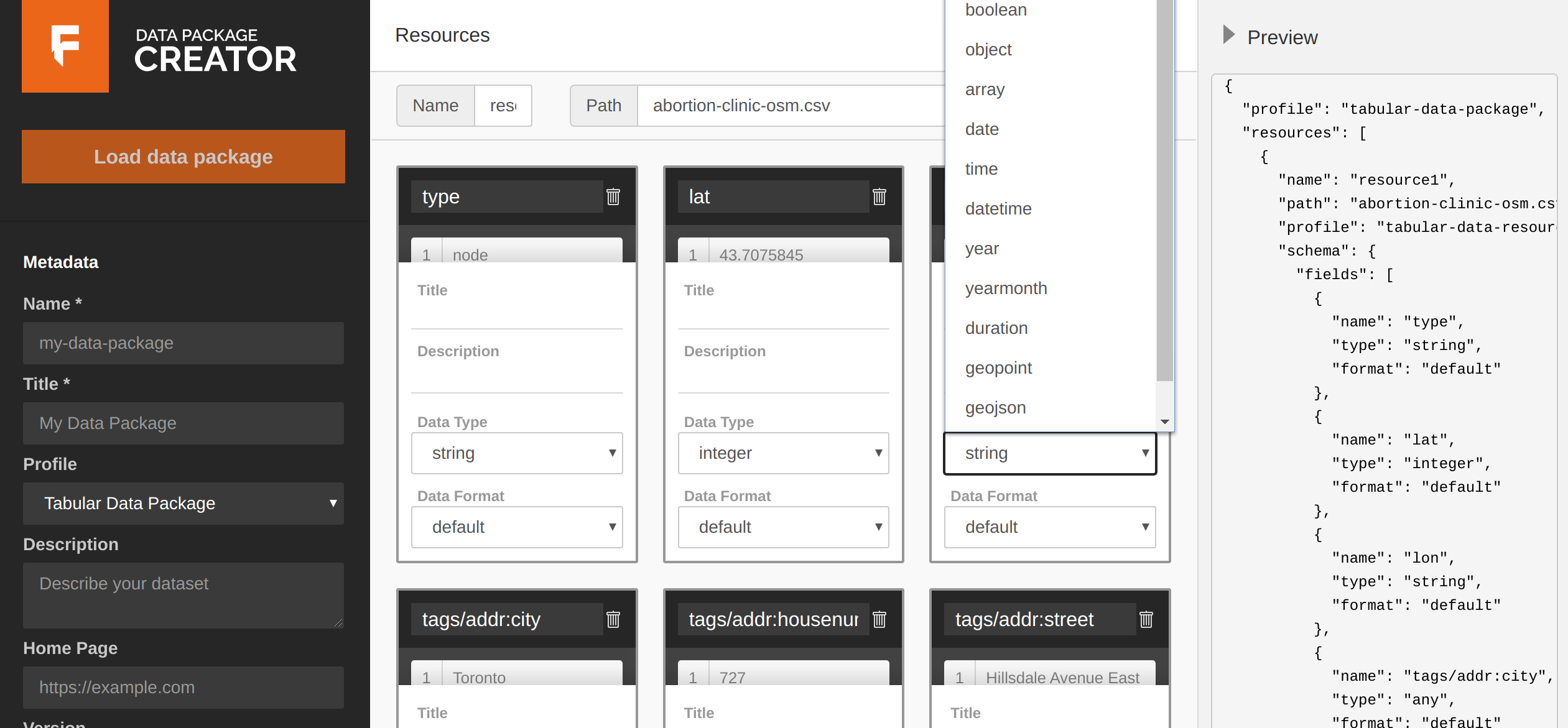
Al descargar los datos desde Overpass Turbo en formato CSV, cargamos la base a la plataforma web para crear los datapackages y validar los tipos de datos que cargamos. Aquí se pueden sumar palabras clave a tus metadatos, el tipo de licenciamiento y puedes descargar tu paquete completo (muy genial, ¿no?) validado.
La plataforma para crear tus datapackages
*Una pista, cuando carguen los nombres y títulos del datapackage, no utilizar mayúsculas, tildes o caracteres especiales porque va a saltar un error de validación aunque tus datos estén correctos.
Data package is invalid!
Descriptor validation error:
String does not match pattern: ^([-a-z0-9._/])+$ at "/name" in descriptor
and at "/properties/name/pattern" in profile
Validación desde plataformas externas
Al cargar tu base de datos, se crearán diferentes casillas con cada una de tus columnas, ahí se puede cambiar el tipo de dato, el formato, añadir títulos y descripciones de los mismos. También, en caso de necesitar limpiar tu base de datos se pueden eliminar columnas. Si quisieras validar tus bases de datos, podés utilizar las Pruebas de Goodtables en formato de prueba única de validación, y también la versión de Goodtables desde donde podés conectar tu github y validar permanentemente tus bases de datos en casos de cambios que realices en tu repositorio.
Para las personas que son técnicamente un poco más avanzadas, pueden probar las librerías de Python, R, y también con Clojure y Java y hacer magia con sus datapackages.
Conclusiones
Para las personas que no tenemos grandiosas capacidades técnicas, esta opción de traslado de datos y validación con una plataforma amigable y sin tener que adentrarnos a las penumbras de nuestras terminales, es de gran ayuda para mejorar prácticas de reproducción de datos, resultados y poder compartir de forma más ágil.
Este tipo de iniciativas de reproducibilidad de datos son de suma importancia para mejorar las prácticas dentro de la ciencia, prácticas comunitarias que aporten a compartir y difundir conocimiento. Empaquetar datos contribuye a estas prácticas, a eliminar la posibilidad de perder información, y al mismo tiempo mejorar la posibilidad de reproducir los pasos que nos llevan a nuestras bases.
En conclusión, si vamos al supermercado, ¿qué es mejor? ¿regresar a casa cargando con todas las compras dispersas, donde se pueden perder, caer, arruinar, o regresar con una bolsa organizada que también se le puede prestar a los vecinos para ir a hacer sus compras luego?
Para ver mi datapackage y toda la información, pueden acceder desde mi Github.
English Version: How do we package data and why is it important to organize the grocery bag?
This is a publication to share with you the process and steps to create datapackages. What is that? A datapackage is basically a package that streamlines the way we share and replicate data. It is like a data container ready to be transported on the highway of knowledge (geeky, right).
Why do we want to package this data? Because with the fellows, we want datasets that are frictionless, that is to say, that can be replicated, reusable and thus contribute to better processes in which knowledge can be opened and shared. If you check the field guides, you can find more information about the program.
The datapackages can contain the data in CSV (comma separated values) format, the data schemes in JSON format and the metadata of your... data...
My datapackage corresponds to geospatial data about abortion centers (clinics) around the world that are mapped on OpenStreetMap. I got this data in a very simple way, I used the Overpass Turbo API with this query (thanks to the help of Geochicas) which yielded 101 mapped nodes. Here is when the validation and packaging of the data begins.
Now, why did I decide to use this dataset? Because my doctoral research and the work that we carry out from Geochicas, seeks to link spatial analysis between the type of objects mapped, the gender of the person mapping those points and also the gender representations that exist in space.
The data resulting from the search made through Overpass Turbo, can be downloaded from the same API, in the following formats: GeoJson, GPX, and KML. You can also download the map displays and the search text.
The query is:
/*
This has been generated by the overpass-turbo wizard.
The original search was:
“healthcare:speciality=abortion or name like abortion”
*/
[out:json][timeout:900];
// gather results
(
// query part for: “"healthcare:speciality"=abortion”
node["healthcare:speciality"="abortion"]({{bbox}});
way["healthcare:speciality"="abortion"]({{bbox}});
relation["healthcare:speciality"="abortion"]({{bbox}});
// query part for: “name~abortion”
node["name"~"^abortion*"]({{bbox}});
way["name"~"^abortion*"]({{bbox}});
relation["name"~"^abortion*"]({{bbox}});
);
// print results
out body;
>;
out skel qt;
When downloading the data from Overpass Turbo in CSV format, we upload the base to the Data Package Creator web platform to create the datapackages and validate the data types we upload. Here you can add keywords to your metadata, the type of licensing, a title and description to each column and you can download your complete package (very cool, right?) validated.
The platform to create your datapackages
*A hint, when loading the names and titles of the datapackage, do not use capital letters, accents or special characters because it will give back a validation error even if your data is correct.
Data package is invalid!
Descriptor validation error:
String does not match pattern: ^([-a-z0-9._/])+$ at "/name" in descriptor
and at "/properties/name/pattern" in profile
Validation from external platforms
When you load your database, different boxes will be created with each of your columns, you can change the type of data, the format, add titles and descriptions of them. Also, in case you need to clean your database you can edit and delete any columns. If you want to validate your databases, you can use the Try Goodtables tool in a unique validation test format, and also the version of Goodtables from where you can connect your github and permanently validate your databases in case of changes in your repository.
For people who are a bit more technically advanced, you can try the libraries of Python, R, and also Clojure and Java and do a little bit more magic with your datapackages.
Conclusions
For people who do not have great technical capabilities (like me), this option of data transfer and validation with a friendly platform and without having to go into the depths of our terminals, is a great help to improve and share data reproduction practices, results more quickly and efficiently.
This kind of data reproducibility initiatives are of great importance to improve scientific communities practices that contribute to the sharing and dissemination of knowledge. Data packaging contributes to these practices, eliminating the possibility of losing information, and at the same time improving the possibility of reproducing the steps that lead to our bases.
In conclusion, if we go to the supermarket, what is better: to return home carrying all the groceries in our hands without a bag, where they can get lost, fall, be ruined, or return with an organized bag that can also be lent to the neighbors to go shopping later?
To see my datapackage with all of the data, you can access it from my Github.