Let's Talk Data Packaging
Packaging of data is the practice of using data packaging tools to containerize data with all its required metadata in the most convenient format that is both human- and machine readable. Packaging removes kinks and ambiguity that comes up when dealing with multivariate data. It additionally ensures that the data does not suffer mishandling and misinterpretation in the hands of others.

Messy data? No problem!
A few weeks ago I met data packages for the first time and I was intrigued since I had spent too much time in the past wrangling missing and inconsistent values. Packaging data therefore taught me that arranging and preserving data does not have to be tedious anymore. Here, I show how I packaged a bit of my data (unpublished) into a neat json document using the Data Package creator . I am excited to show you just how much I have come from knowing nothing to being able to package and extract the json output.
Here we go!
The Data Package Creator
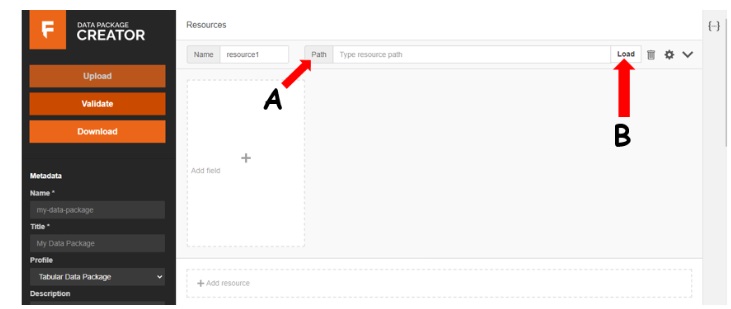
The Data Package Creator user interface.
This is a friendly user interface that was created by the open knowledge foundation to enable a quick and easy route to creating and accessing a datapackage. It therefore allows coders and non-coders alike to be able to do this without breaking a sweat. First, the data needs to be loaded into the system and the Path (A) section comes handy in this. You can either paste a github url or use the Load (B) section to access the csv file from your remote machine.
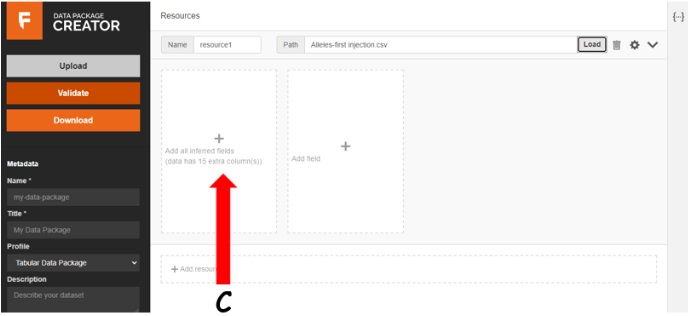
Automatically inferred data fields.
I loaded data from my PC and the system automatically inferred 15 fields for me. I then defined my fields using the settings wheel that enabled me to input the name and the schema. My work is in a tabulated format so the tabular data package was fitting.
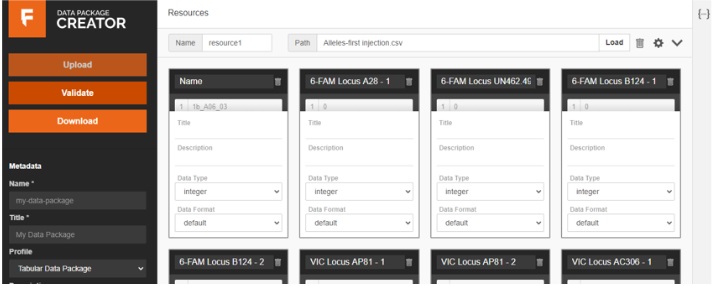
The data fields section that supports editing by user.
In the metadata section I also inferred the name and title, a short description of the data package, the versions and licences and finally the keywords. I then checked if all the fields that were inferred from my dataset were okay and pressed validate.
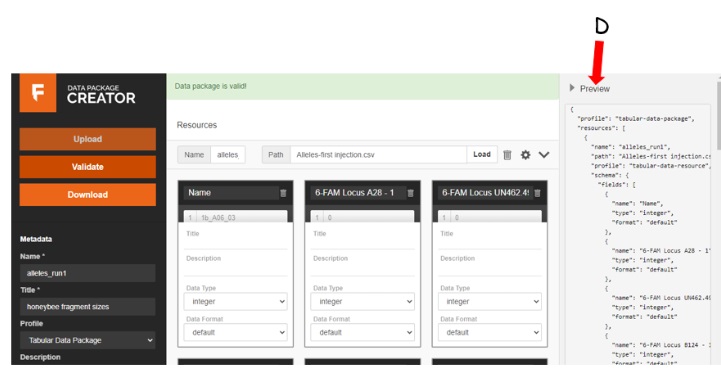
Data Package is valid!
Pretty straightforward, right? Yes.
After validating, I wanted to see how my json file looked and also download it for storage in my PC or share on github. Clicking on the {...} symbol allowed me to sneak a peek at my new json file while the Download button just...downloaded it.
This process took me like 10 minutes to complete and it had everything I needed!
You can also learn to create your packages in R and Python from the Frictionless fellows website
Setbacks
You got to get the names right; as in the Resources and Name section. Underscores (_) and dashes (-) really got me wound up on this one. Either way a warning will be displayed at the interface so fixing this won’t take much of your time.
In a nutshell…
Good data needs to be well packaged for posterity, let’s all adopt this important practice for better research.