How to share data and code in a ‘Data Package’?
What is a Data Package?
A Data Package is a simple container format used to describe and package a collection of data. It consists of a descriptor (a JSON file) that provides general metadata describing the structure and contents of the package, and resources such as data files that form the contents of the package. Below presents how a Data Package may look like.

Data Package tool
There are several ways to create a Data Package: Data Package Creator, R, Python, etc. Data Package Creator is a free, online service that easily allows users to create a Data Package from their datasets. Because Data Package Creator is a browser tool that has an intuitive workflow, I am going to use this tool to create a Data Package.
Create a Data Package
Prepare dataset
The dataset I am going to package is from a project which we have recently completed – “Menopausal hormone therapy and women’s health: An umbrella review” which summarizes the clinical evidence on various health effects of menopausal hormone therapy in menopausal women. The full datasets are publicly available in the Open Science Framework. I am going to use one of the datasets –All-Cause Mortality.xlsx, which summarizes all the clinical trials published until 2017 investigating the effect of menopausal hormone therapy on all-cause mortality in menopausal women – to illustrate the process of creating a Data Package. The dataset can be directly downloaded here.
As the Data Package Creator currently accepts only .csv format, first I need to convert All-Cause Mortality.xlsx to .csv format. The conversion can be easily done in Excel: File –> Save As, in the pop-up window, find and choose ‘Comma Separated Values’ in the File Format list. In the converted file, it is obvious to notice that the dataset has two extra rows in the beginning and two extra columns in the end. So, I am going to delete all the extra rows and columns. Now, I am ready to use All-Cause Mortality.csv to create a Data Package.
Data Package Creator
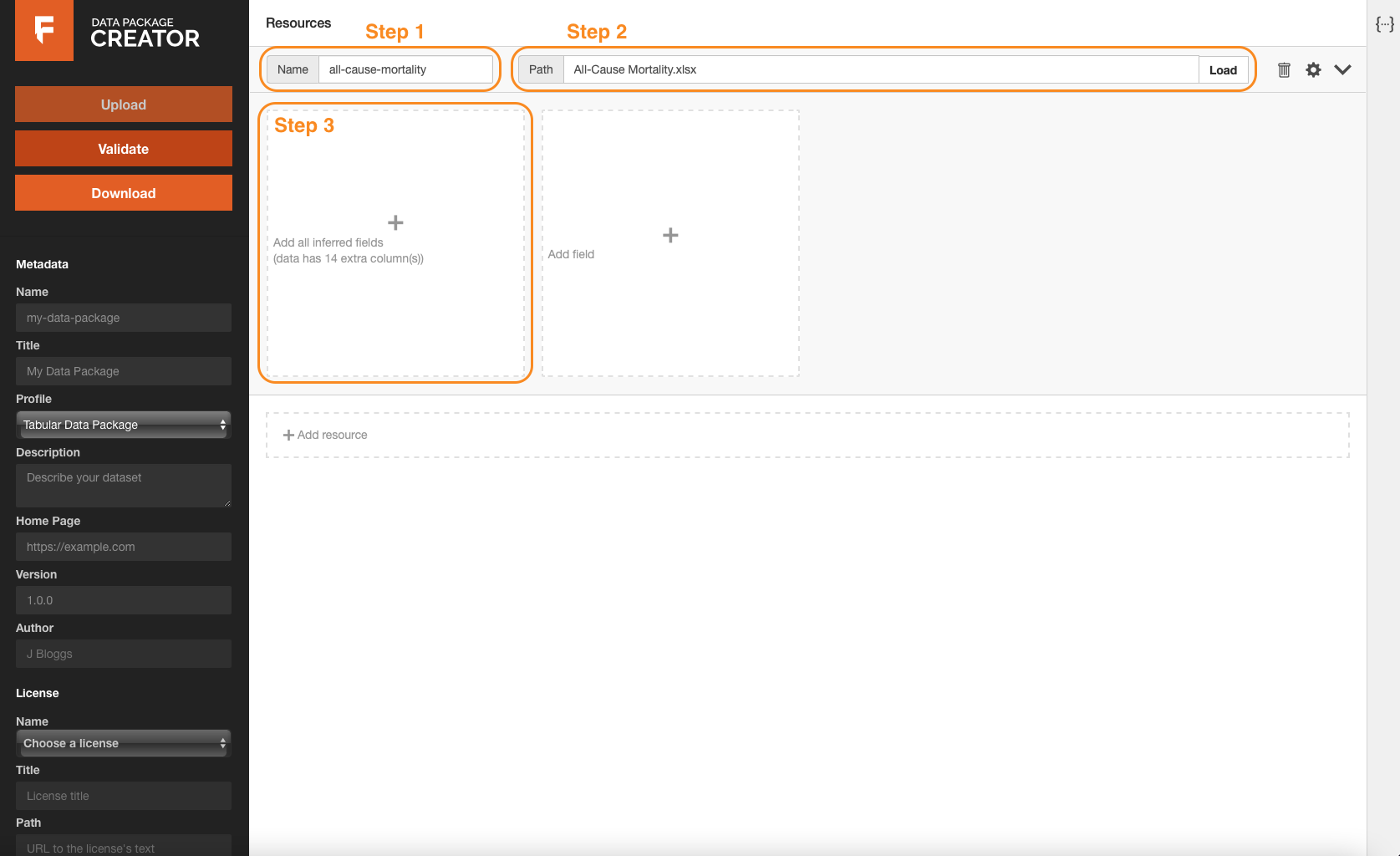
Step 1: Name the resource ‘all-cause-mortality’.\ Step 2: Import the dataset All-Cause Mortality.csv.\ Step 3: Add all the inferred fields from the imported dataset.
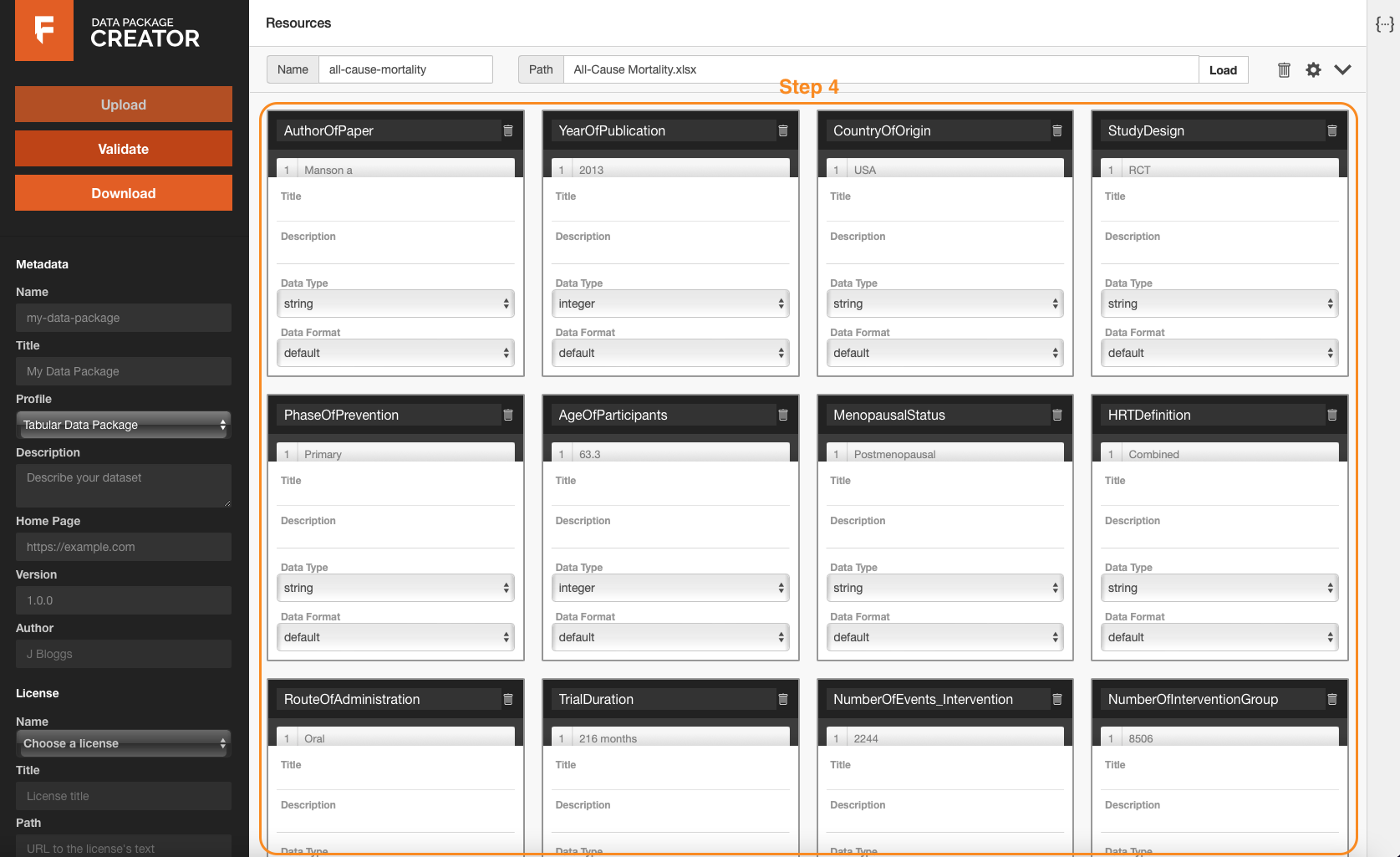
Step 4: Check the inferred fields. For example, I need to check if data types for all the variables have been inferred properly. I can see that the data type for the variable “AgeOfParticipants” should be ‘number’ instead of ‘integer’. So, I need to change it to ‘number’. At this step, I can also provide additional information for each variable by adding title and description.
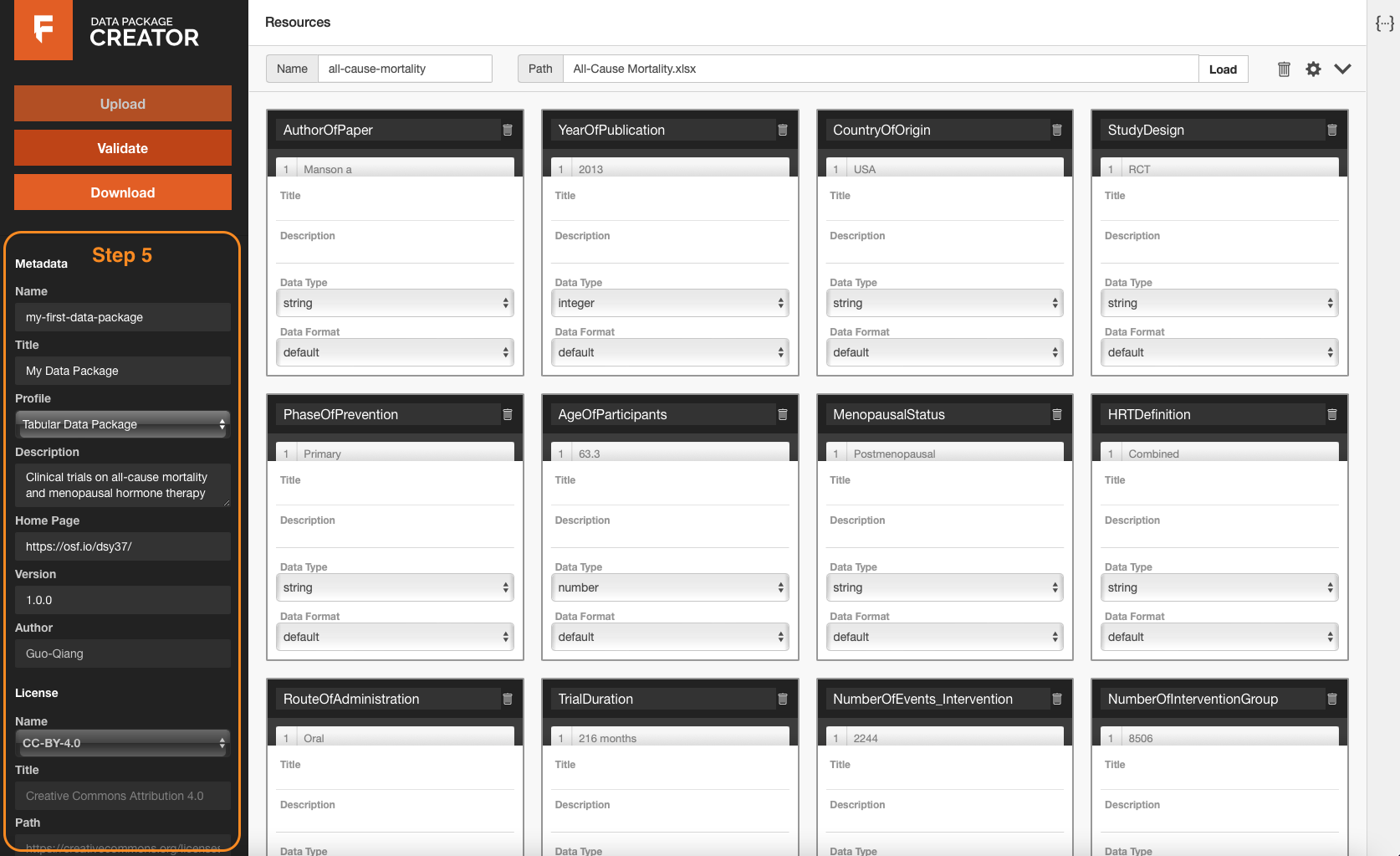
Step 5: Fill in metadata, such as name and title of Data Package, description, author, license, etc.
Step 6: Validate Data Package. If the created Data Package is valid, a message “Data Package is valid” will show up.\ Step 7: Download descriptor (JSON file).\ Step 8: Package descriptor, dataset, and analysis code. Below shows the completed Data Package.