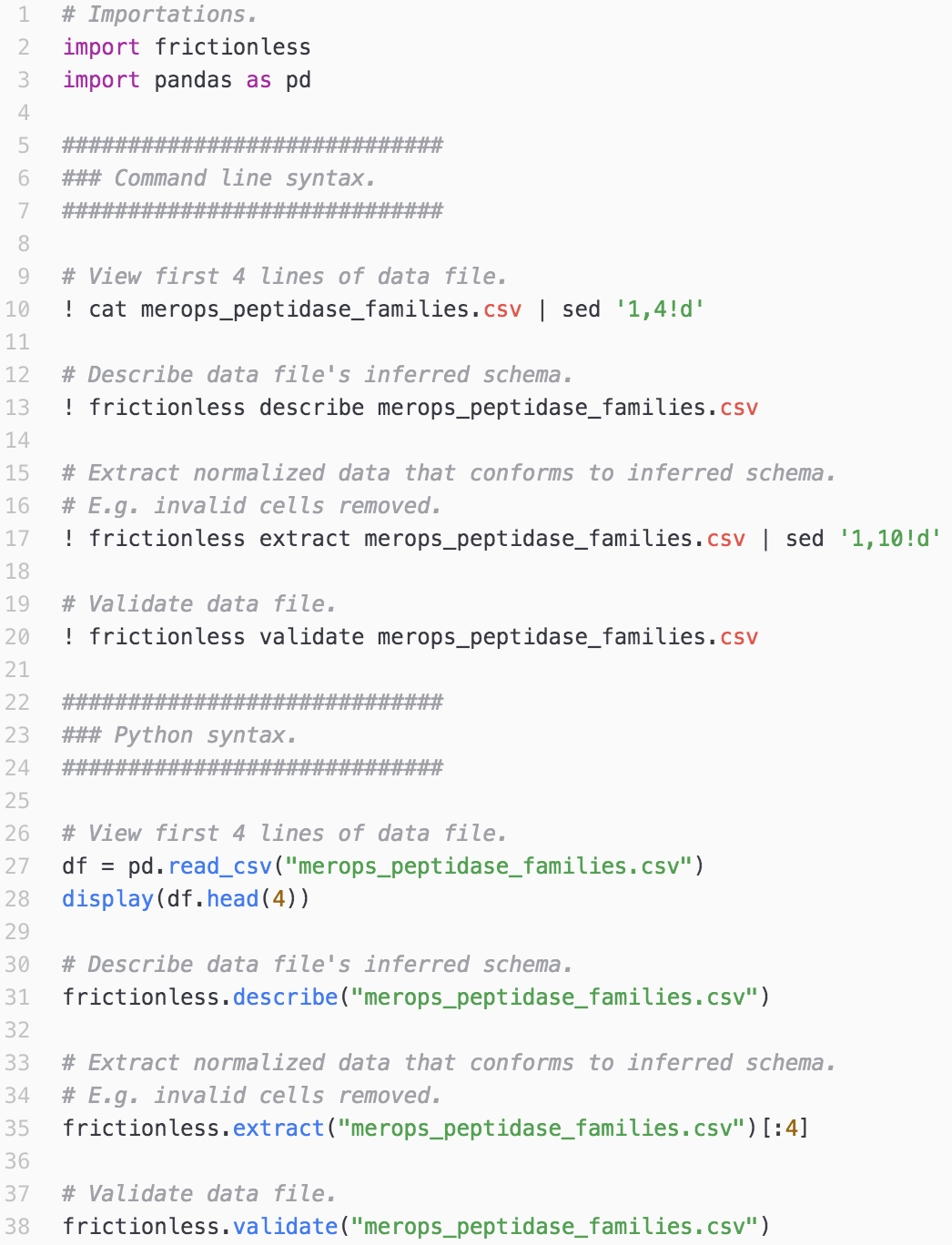
Walking through the `frictionless` framework
While the GoodTables web server is a convenient tool for automated data validation, the frictionless framework allows for validation right within your Python scripts. We'll demonstrate some key frictionless functionality, both in Python and command line syntax. As an illustrative point, we will use a CSV file that contains an invalid element – a remnant of careless file creation.
View the original Jupyter notebook, Python script, and dataset on GitHub.
Note: This demo uses frictionless version 3.48.0, pandas version 1.0.1, and Python 3.8.3.
Overview
This simple Python script shows the command line syntax and equivalent Python syntax that we will review in this demo.
Command line syntax
View data
First, we will import the frictionless package. We will also use pandas for some light dataframe manipulation. Starting with our command line syntax, we can get a sense of what we are working with by printing out the first several lines of our CSV file.
If you look closely, you will see that the first column contains no header: the first element of the first row is empty, as conveyed by the lonely , preceeded by... nothing at all. In fact, this column is quite useless: it is an artifact of forgetting to pass the argument index = False to the pandas function to_csv() during file creation. This useless indexing column would ideally be removed entirely. Let's see how this oversight plays out during file validation...
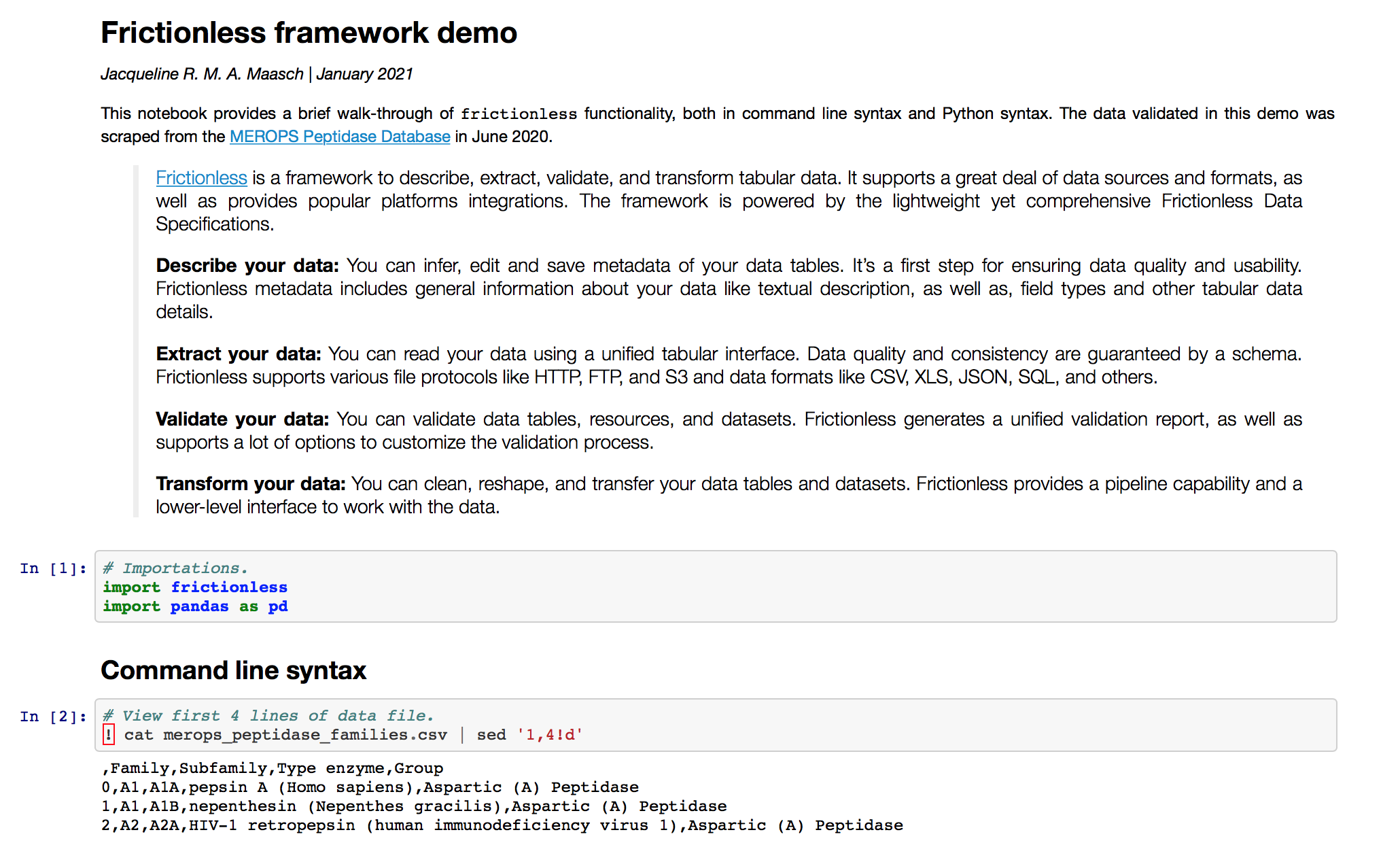
Describe data
Next, we can describe our data file. This is a convenient way to view inferred header names and column data types, for example.
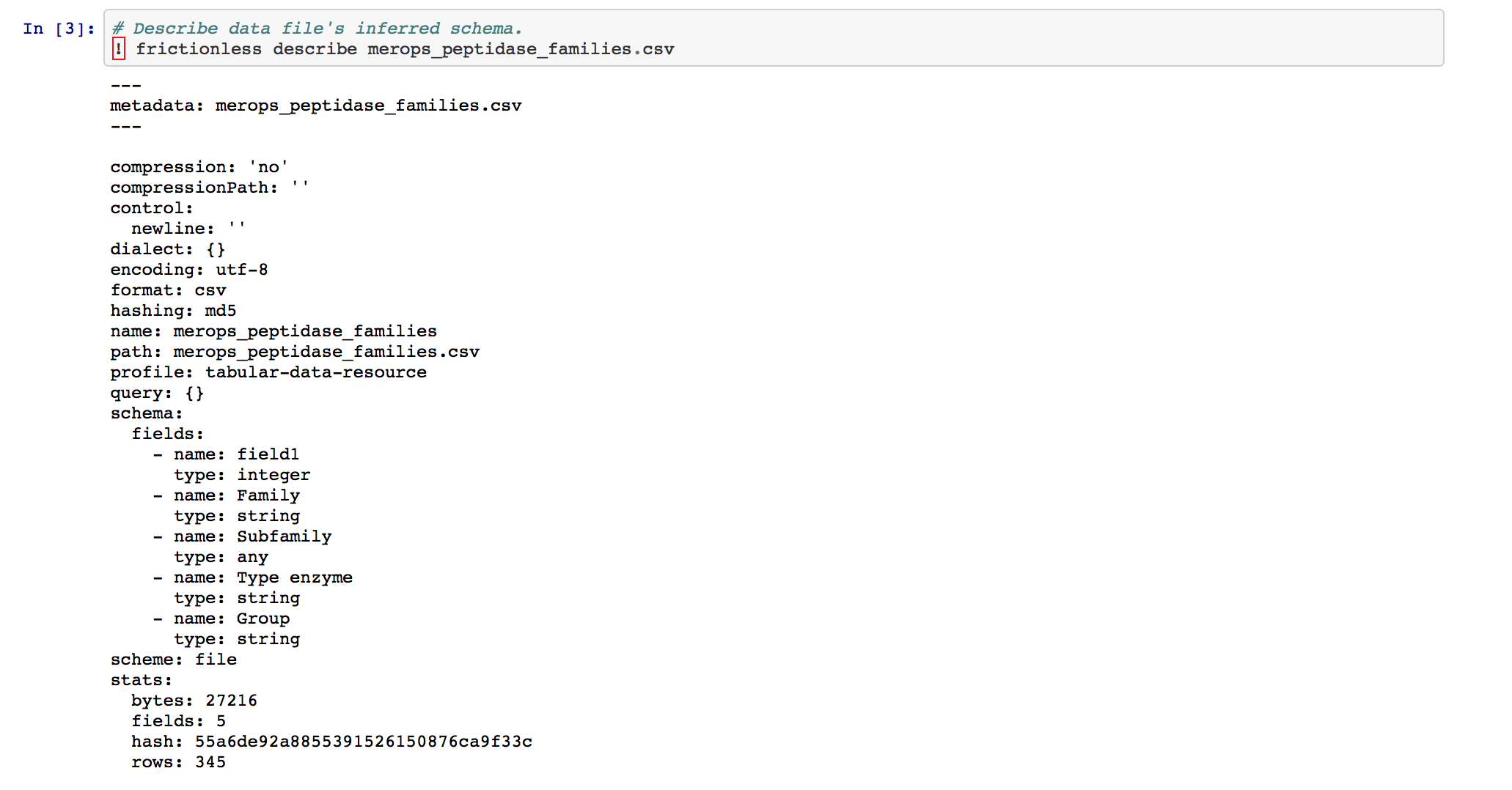
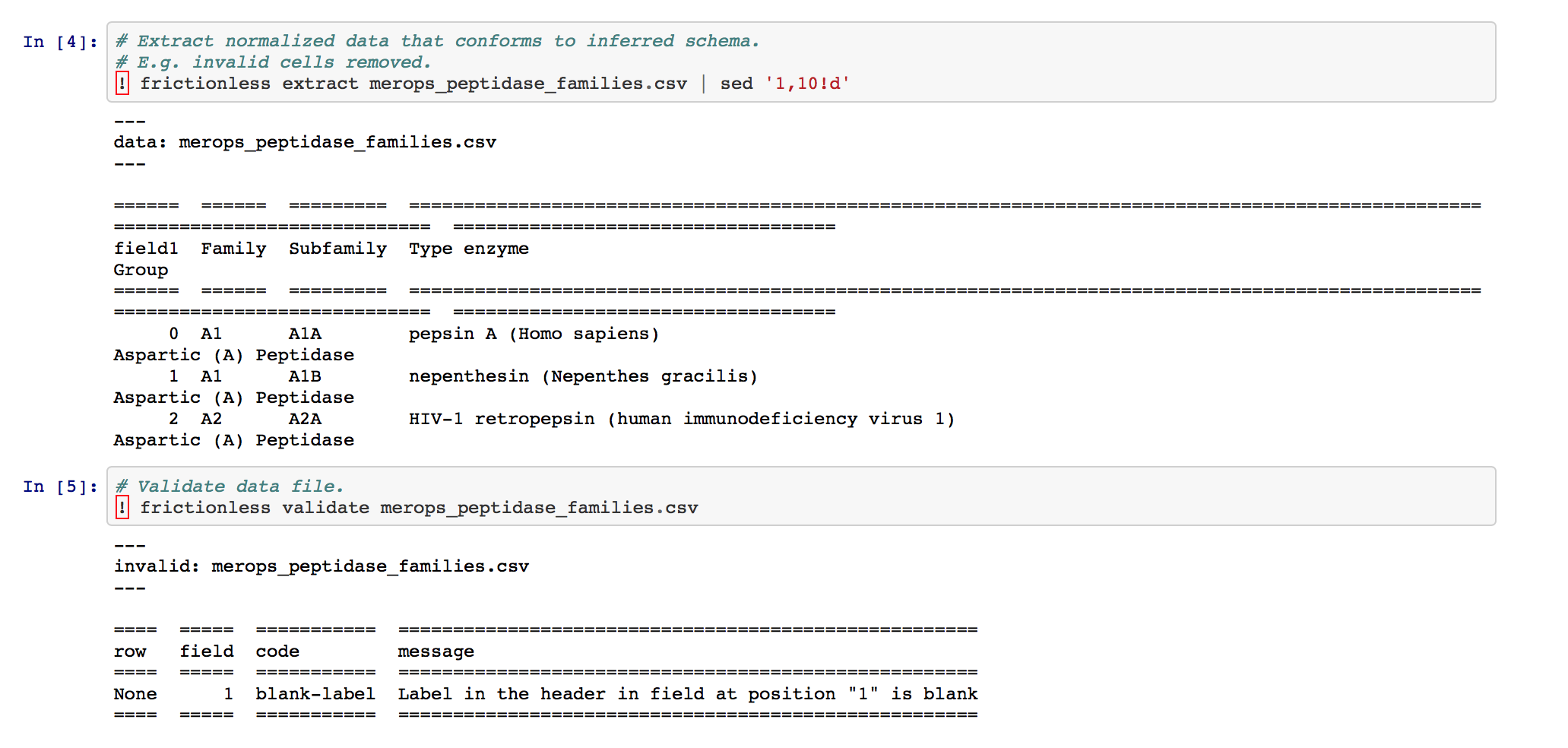
Validate data
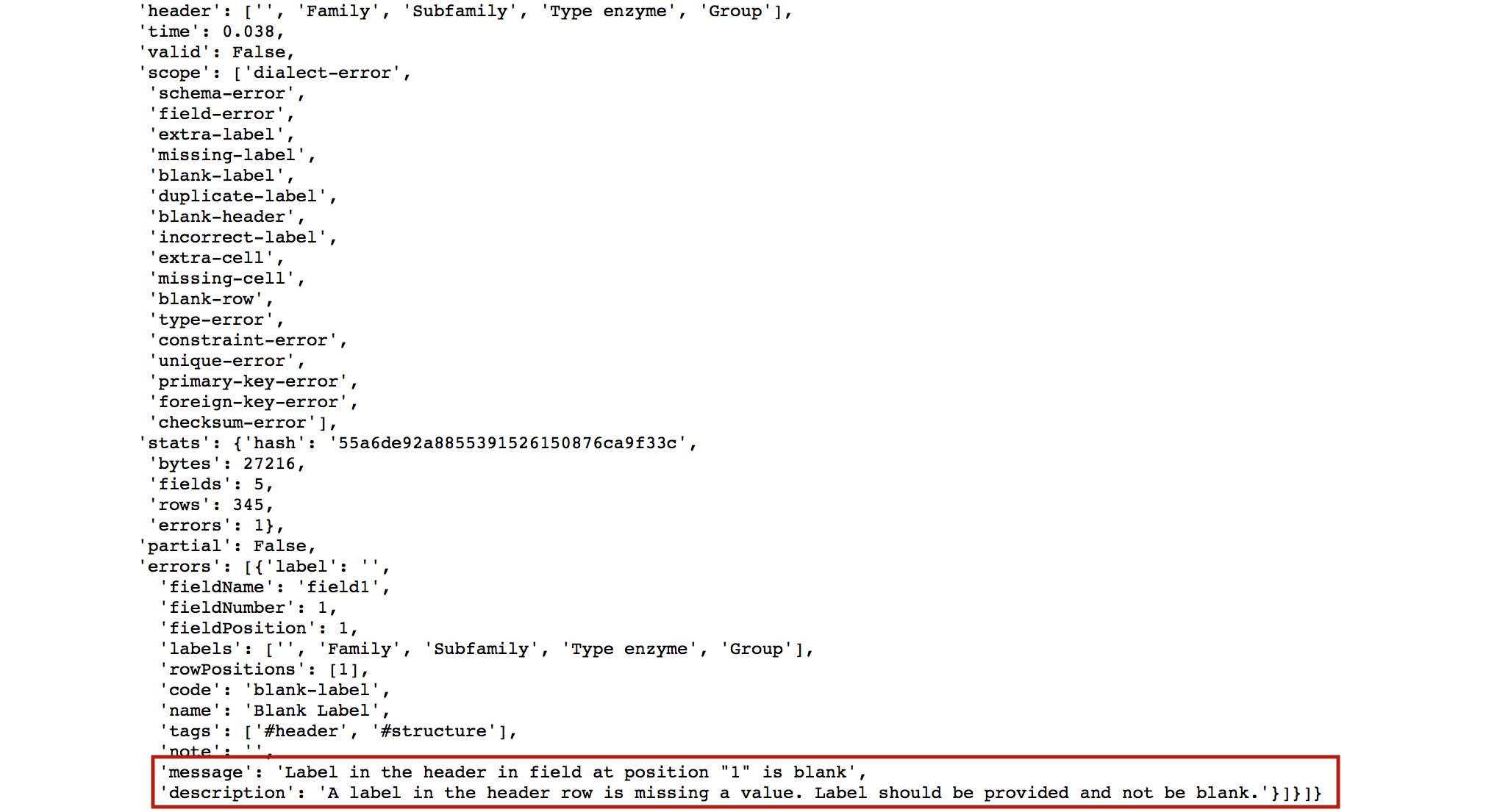
When we finally validate our data file, that missing column name that we noted above will come back to haunt us... indeed, this is the cause of our failed validation. To make this CSV file valid, we would need either to 1) remove the offending column, which contains no pertinent data anyways, or 2) give the offending column a proper header.
Python syntax
Below, we walk through the Python syntax that provides equivalent functionality. As you'll see, this syntax is extremely similar to its command line equivalent, just more "pythonic." However, the outputs do look a bit different!
Note that the header of our headerless first column is autopopulated by pandas as Unnamed: 0. Don't be fooled: this column is still technically headerless.
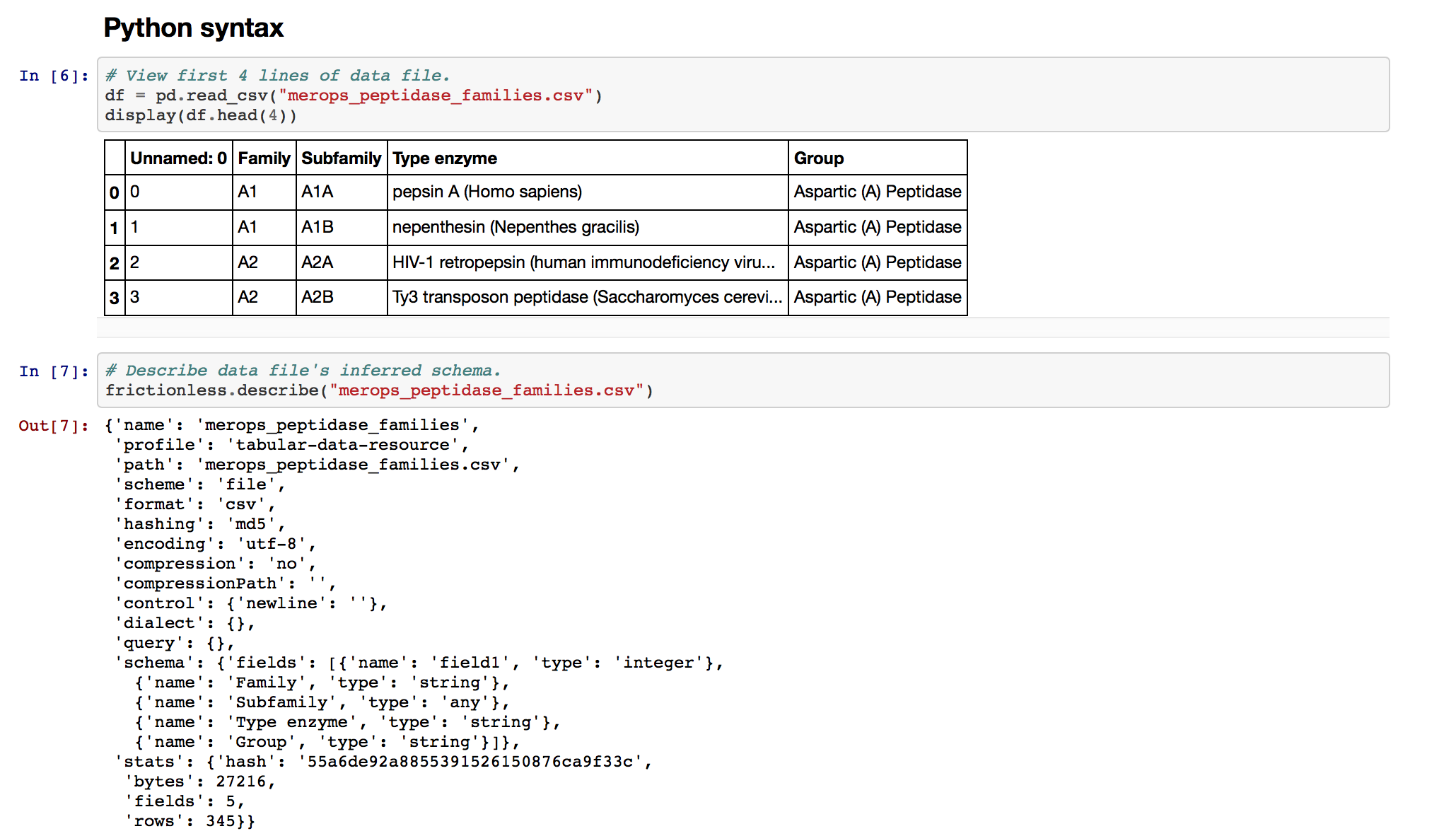
Clearly, our data is invalid!
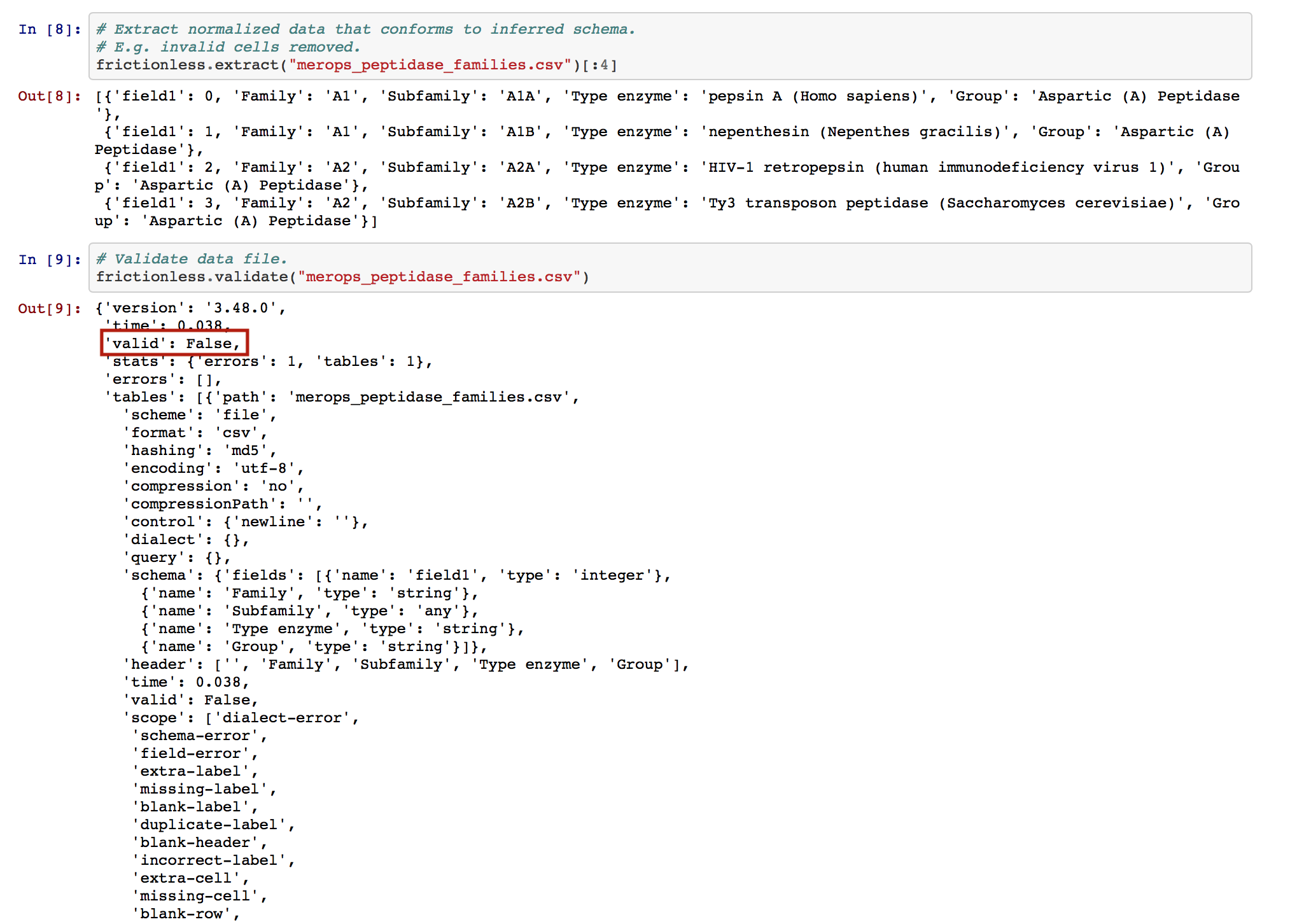
Note that the message and description values provide a useful elaboration on why our CSV file is deemed invalid.
Bottom line
The frictionless framework is a convenient way to wrap your data validation needs directly into your existing Python data analysis pipeline. Choose whichever syntax works for you – Python or command line.