Reproducing a data package
Is it easy to reproduce someone else's data package? Sometimes, but not always. Tools that automate data management can standardize the process, making reproducibility simpler to achieve. However, accurately anticipating a tool's expected behavior is essential, especially when mixing technologies.
Let's try to reproduce a data package created by Kate, another fellow. We will do so by using a combination of Python and the Frictionless Data Package Creator. Let's see if we experience any conflicts by mixing these tools. Kate has provided three CSV files and a JSON file describing her inferred schema, which ours must match.
Getting started in Python
First, we will import the Python packages that we need: datapackage for data package construction, frictionless for data file validation, and pandas for light dataframe manipulation.

Read data
Next, we will import our data files and explore them. When validating our CSV files with frictionless, we happily observe that all three are valid.
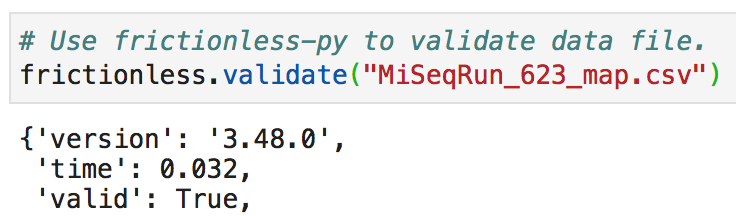
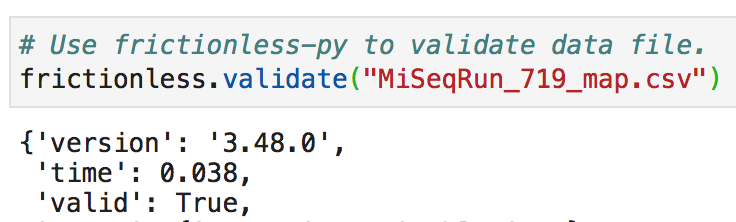
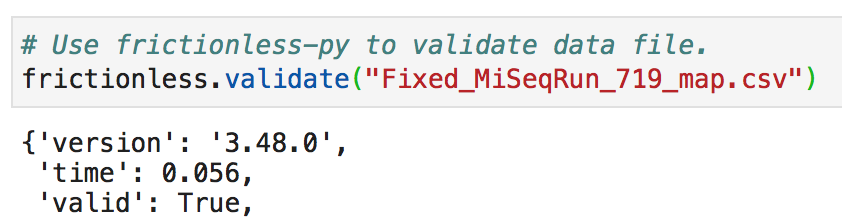
However, when exploring our dataframes with pandas, we note that df_623 and df_719 do not have the same column headers nor the same shape. This makes analyses that draw comparisons between the two datasets less convenient. Therefore, Kate has created df_719_adj, which has adjusted df_719 so that it adheres to the same format as df_623.
df_623
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sample_name 30 non-null object
1 golay_index_barcode 30 non-null object
2 primer_name 30 non-null object
3 full_primer_sequence 30 non-null object
4 sample_id 30 non-null object
5 DNA_conc 30 non-null float64
6 is.neg 30 non-null bool
7 sample_origin 30 non-null object
8 anti_coagulant 18 non-null object
9 subject_id 30 non-null object
10 extraction_batch 30 non-null int64
11 dna_extraction_kit 30 non-null object
dtypes: bool(1), float64(1), int64(1), object(9)
df_719
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 samle_name 95 non-null object
1 sample_description 95 non-null object
2 sample_ID 95 non-null object
3 barcode 95 non-null object
4 is.neg 95 non-null bool
5 DNA_Conc 95 non-null float64
6 sample_origin 95 non-null object
7 extraction_batch 68 non-null float64
8 dna_extraction_kit 95 non-null object
dtypes: bool(1), float64(2), object(6)
df_719_adj
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sample_name 95 non-null object
1 golay_index_barcode 95 non-null object
2 primer_name 95 non-null object
3 full_primer_sequence 95 non-null object
4 sample_id 95 non-null object
5 DNA_conc 95 non-null float64
6 is.neg 95 non-null bool
7 sample_origin 95 non-null object
8 anti_coagulant 34 non-null object
9 subject_id 95 non-null object
10 extraction_batch 68 non-null float64
11 dna_extraction_kit 95 non-null object
dtypes: bool(1), float64(2), object(9)
We can test whether our headers are the same as well:

We can then use datapackage to construct our inferred schemas and test whether they are valid.
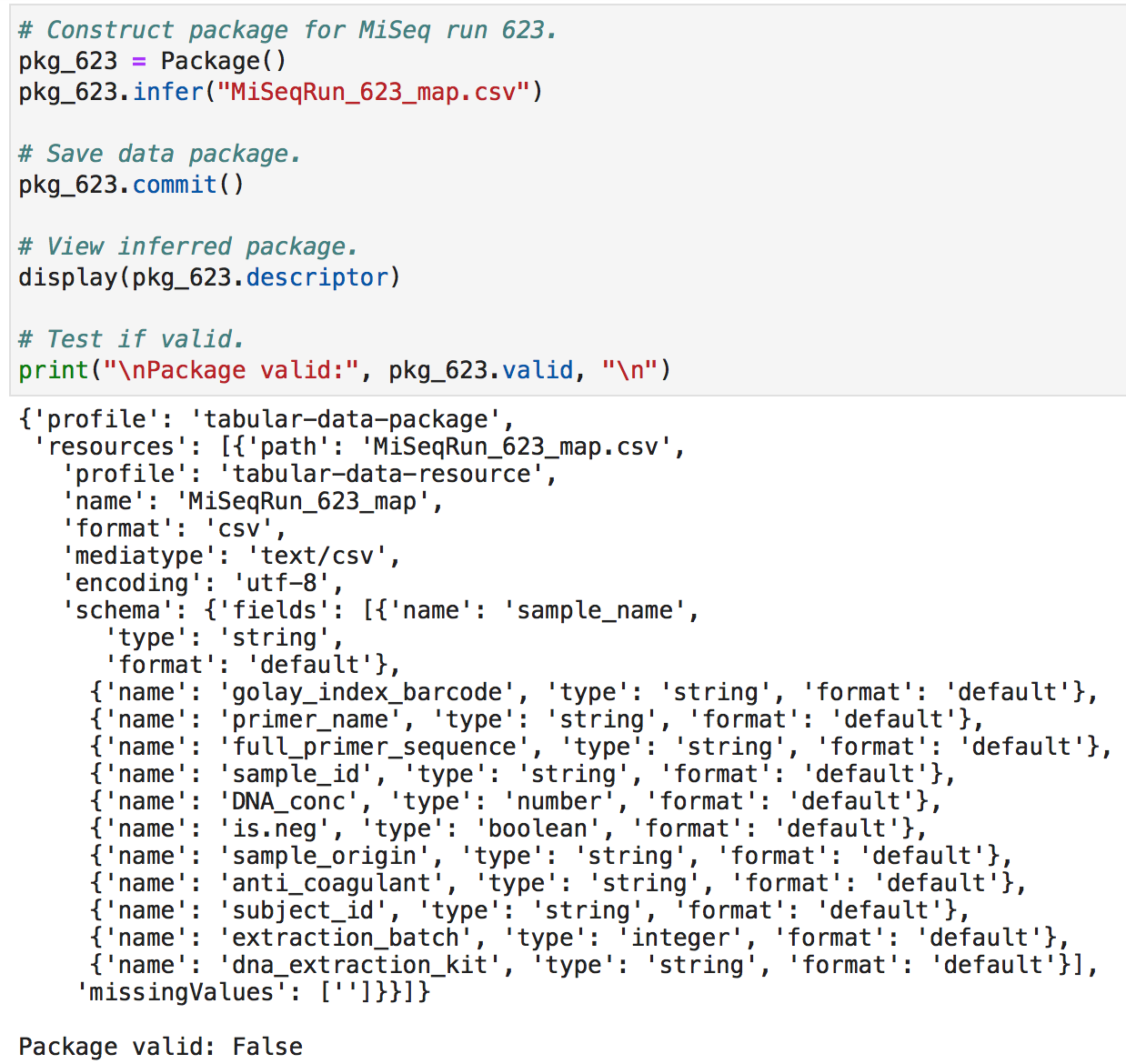
And we have run into our first problem! :) Note that the data package is deemed invalid. This is our first hint that something is off. If you look closely, several of the data types inferred by datapackage in Python are different from the data types in Kate's inferred schema below. For example, the is.neg column contains string values as inferred by Kate's data packaging process, while our process has inferred boolean values. We have failed to reproduce the package faithfully!
Kate's inferred schema
{
"fields": [
{
"name": "sample_name",
"type": "string",
"format": "default"
},
{
"name": "golay_index_barcode",
"type": "string",
"format": "default"
},
{
"name": "primer_name",
"type": "integer",
"format": "default"
},
{
"name": "full_primer_sequence",
"type": "string",
"format": "default"
},
{
"name": "sample_id",
"type": "string",
"format": "default"
},
{
"name": "DNA_conc",
"type": "integer",
"format": "default"
},
{
"name": "is.neg",
"type": "string",
"format": "default"
},
{
"name": "sample_origin",
"type": "string",
"format": "default"
},
{
"name": "anti_coagulant",
"type": "string",
"format": "default"
},
{
"name": "subject_id",
"type": "string",
"format": "default"
},
{
"name": "extraction_batch",
"type": "integer",
"format": "default"
},
{
"name": "dna_extraction_kit",
"type": "string",
"format": "default"
}
]
}
Data Package Creator
We can then turn to the Frictionless Data Package Creator to see if our results match Kate's. We can see that the CSV file that yielded df_623 produces the following inferred data package:
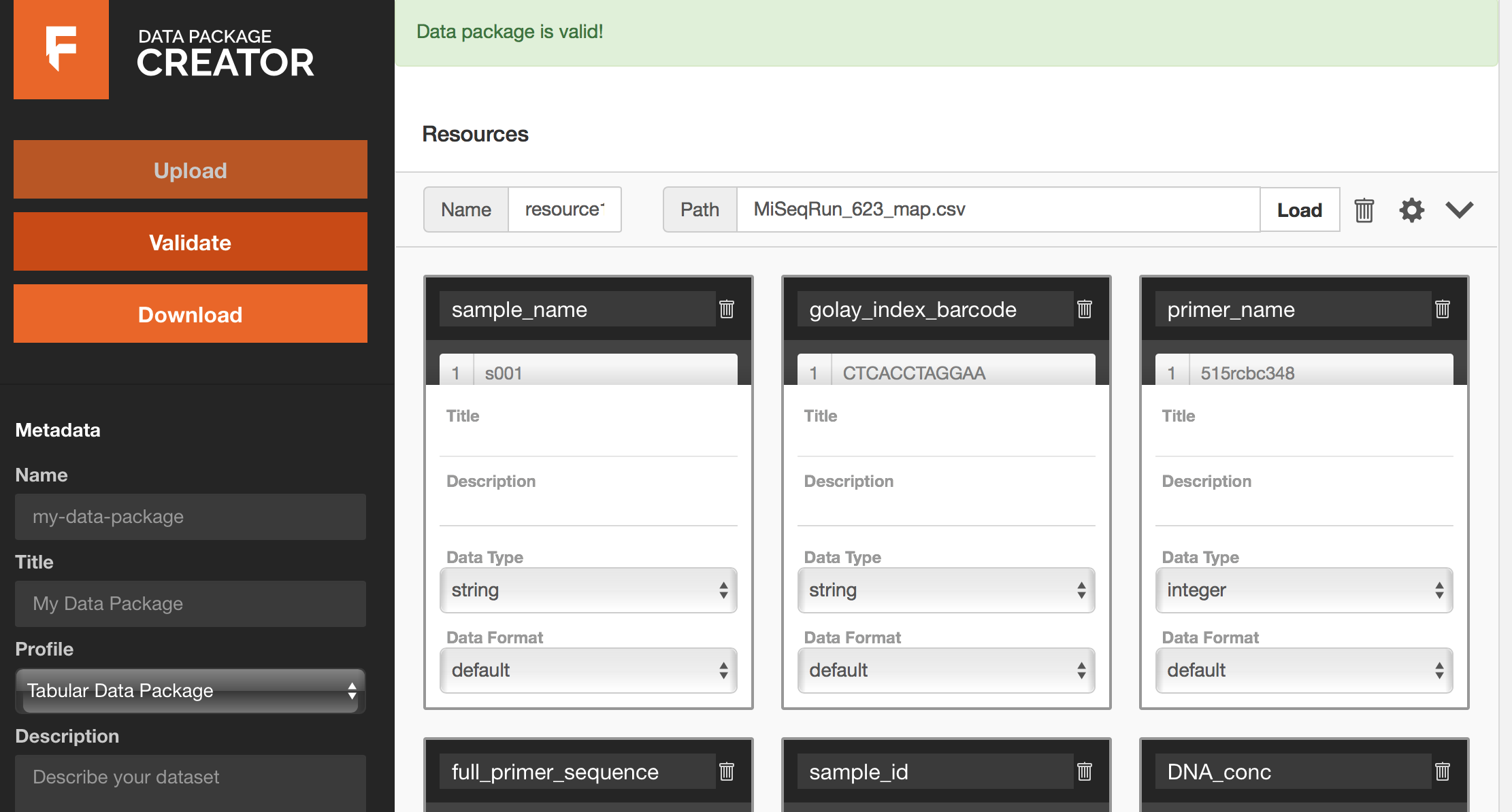
Fortunately, it is valid! When running the CSV file for df_719_adj, we produce an identical data package. The question is: are the inferred schemas in these data packages identical to the schema produced by Kate?
Fortunately, all three UI-inferred data packages contain the same schema that Kate created. And we have successfully reproduced a data package! :)
Lessons learned
If you are reproducing someone else's data package, or if you are creating many data packages that must conform to the same structure, be consistent with which technology you are using. Note that inferences made by the Data Package Creator UI and the Python package datapackage may differ (as of 24 February 2021). Both tools are useful, but stick consistently with one or the other.