So you want to get your data package validated?
The problem
Have you ever found any kind of dataset, (or been given one by your PI/collaborator) and had no idea what the data were about? During my PhD I've had my fair share of not knowing how code works, or how stimuli were supposed to be presented, or how data were supposed to be analysed. The Frictionless Data Fellowship enabled me to change my perspective over why this happens. Initially I would blame myself for not understanding how the code works, or not understanding the paper/dissertation that used the specific stimuli, or not knowing enough statistics for data analysis. This would make me very frustrated and reinforce my impostor syndrome, making me believe that I got where I am by some kind of a mistake.
The solution - Data Package Creator
The datapackage tool tries to solve one of these issues, more specifically creating packages in which data make sense, and have all the explanations (metadata) necessary to understand and manipulate them. Moreover, this solution can be given either in code (Python and R), or with a very pleasant graphical interface (for those of us still working on our programming skills).
A blank data package creator site.
Preparing data for packaging
The data that I packaged for this blog post are a part of my PhD project data: they cover preschoolers' performance on a number of behavioural tasks, covering their language skills, their cognitive (memory and attention) skills, and their music skills. The fellowship had already helped me to manage my data in an optimal way, but I had to create a .csv file that contained all the subtest data. I tried to follow best practices for data management. I also had to make sure that no personal identifying information was in my data.
My .csv file before loading it.
Using the Data Package Creator
If your data are not already published in a repository (like Github, or Zenodo), where you just need to copy and paste the link to their location, you will need to load your data file, and browse through your local directory to upload the file. Once that is done, the Data Package Creator has inferred the columns (from the columns you've so carefully created in your .csv file). So, you click on 'Add all inferred fields'. When you do that, all your columns show up.
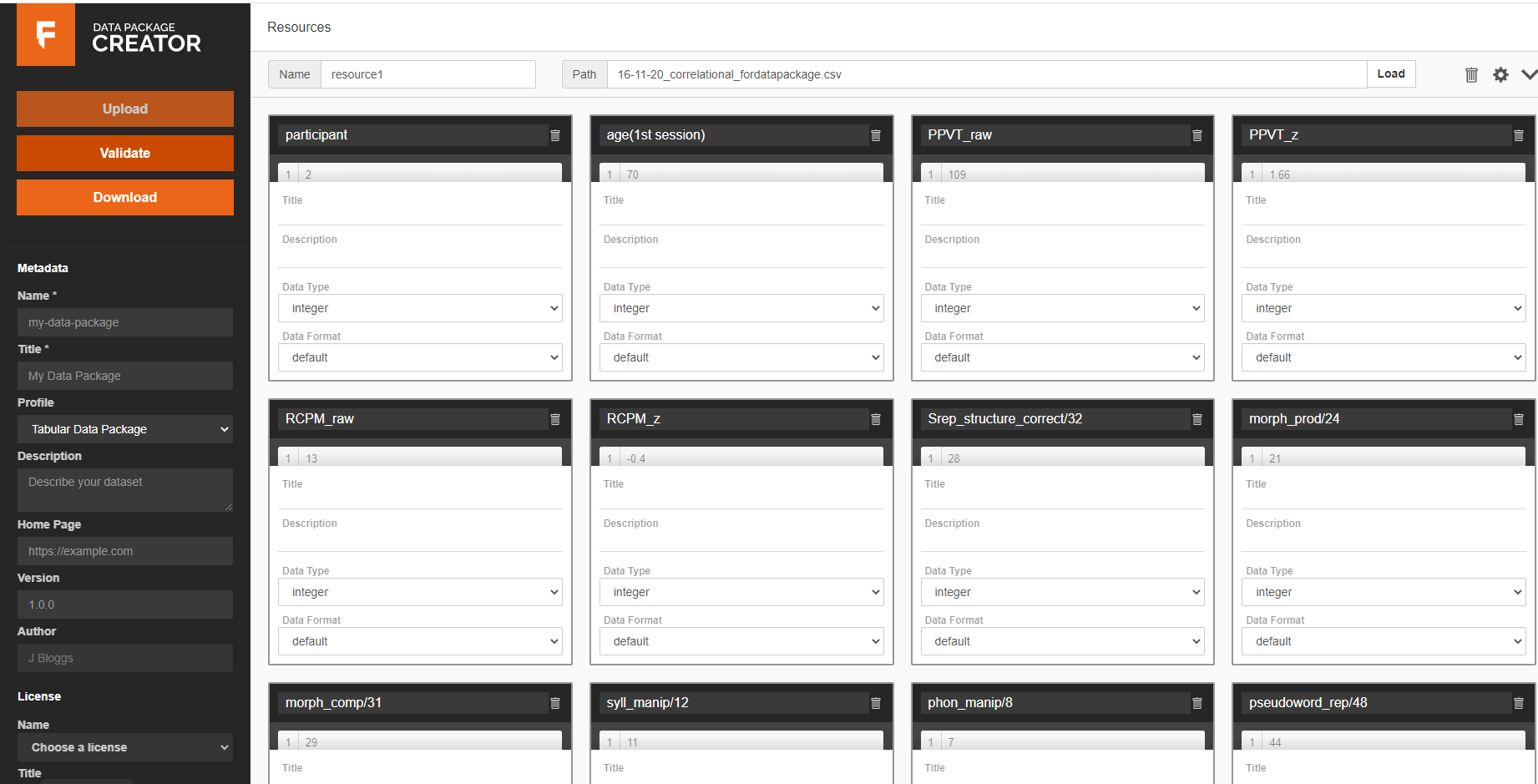
My data package before doing any changes.
The Data Package Creator has done half of your work for you, now you need to go to each of the columns and give additional information on the nature of each column and specify the type of data (this will also come in handy for your data analysis). For example, in the first column ('participant') I will need to clarify that this column contains the participant number allocated to each of my participants. While you work on clarifying what each column is, if you click on the {...} at the top right of the website, you will be able to see the changes to the json schema being made. Be careful specifying correctly the type of your data (e.g. where I had z-scores I had to specify number and not integer). If you have multiple data files, you can upload another resource and infer data from the other one as well.
Once you're done with giving more information about each of the columns, you head to the left side of the creator. There, you need to specify the name of the packaged file, and the title of the package. Be careful not to use special characters, as this might cause a problem in your validation. It will be extremely helpful to provide a description of the project, having in mind researchers who might not be familiar with your tasks. If you have a website dedicated to the project also mention it. Lastly, you can choose what kind of license your data have.
If you think you have everything covered, you hit the validate button!
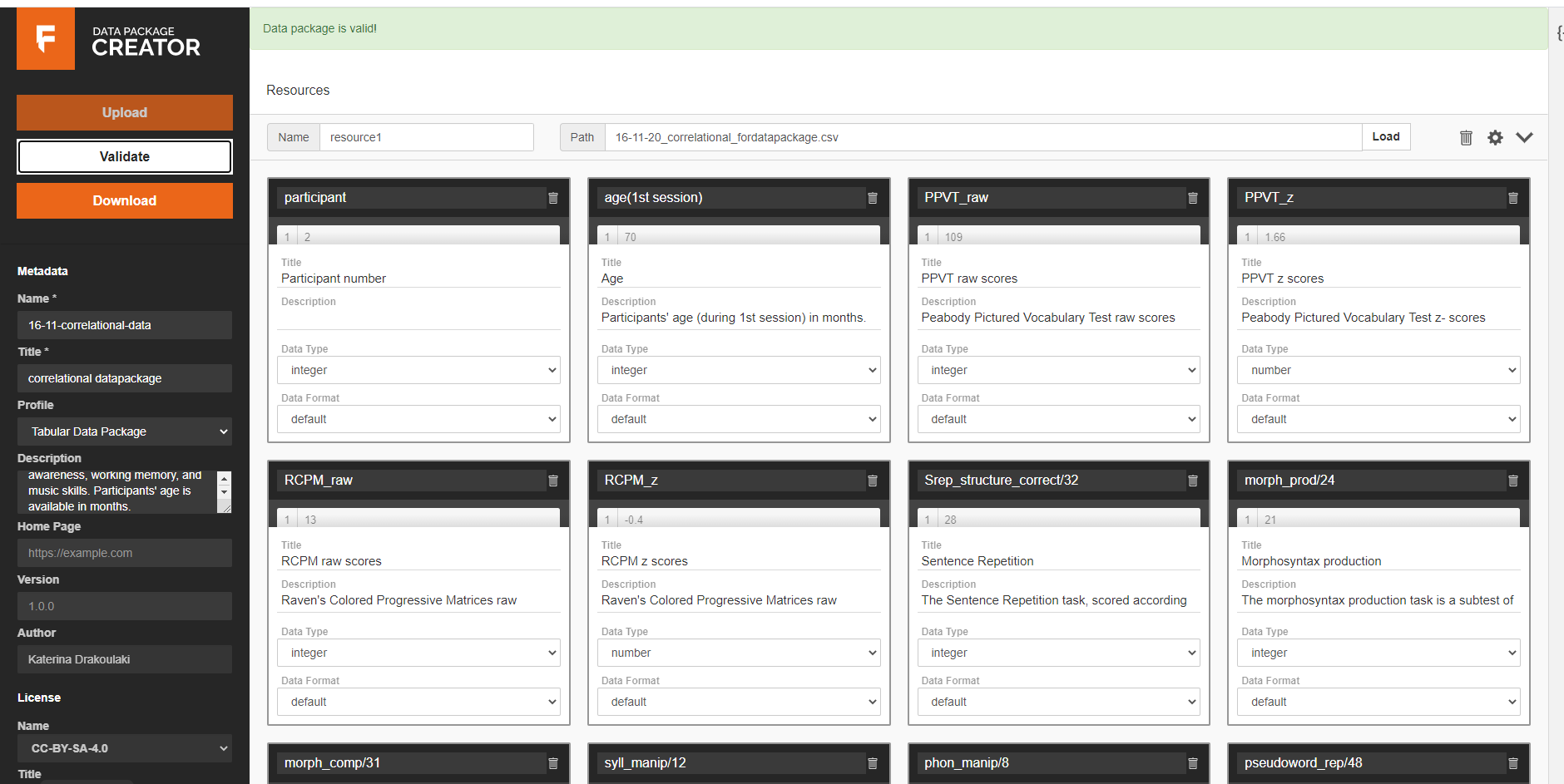
My validated data package.
Then you can download the schema for your data, containing all the extra information you have entered. Your data are ready to either be uploaded to a repository (if they are not already uploaded), or to be sent to your collaborators. My data file, as well as metadata are available here.
Conclusion
To sum up, this was a blog post about my experience with packaging data. I firmly believe that this is a tool to make your data more reproducible and understandable by other researchers. My experience in my PhD project is that not having a specific workflow (or at least documenting your workflow) can make your work very difficult to reproduce. I have already been on the receiving end of difficult to reproduce code/stimuli/data, so I hope that by using tools such as the Data Package Creator I am taking active steps towards being a better researcher! And keeping in mind that these issues are something that everyone faces, and that it's not your fault is definitely helping with having the right mentality to keep pushing forward!