Validating someone else's data!
Validating another fellow's data package
At this point of the fellowship, we were asked to exchange data packages with another fellow and see if we can understand the data, meta-data and if we can validate it.
The README document
The first thing I did was to go through the README file on my fellow's repository. Since the repository was in a completely different field, I really had to read through everything very carefully, and think about the terms they used. When we were talking about exchanging data, I was secretly hoping to not get anything biology related because I thought that that was going to be very difficult for me, coming from the humanities. However, it turns out I was wrong, because even another field such as social science turned out to require a lot of concentration and reading!
Cloning the repository
With validating my partner's data, it made sense to either try one-time validation, or validate via the command line interface (CLI). Being used to validating through CLI (and going through a lot of pains to use the python library), I chose to do it that way.
Understanding the meta-data
Thankfully, my partner had written a super detailed README file (which also made me question the quality of my own README file). When opening their meta-data file, I had to go back to the README file to remember which term referred to what, but I eventually think I understood everything!
Validating the data
One of the things that I found puzzling at first was the fact that my partner had several different .csv files with data (whereas I had all my variables in one). One way this could work was to validate each and every one of them separately:
goodtables asyl-seek-ref.csv
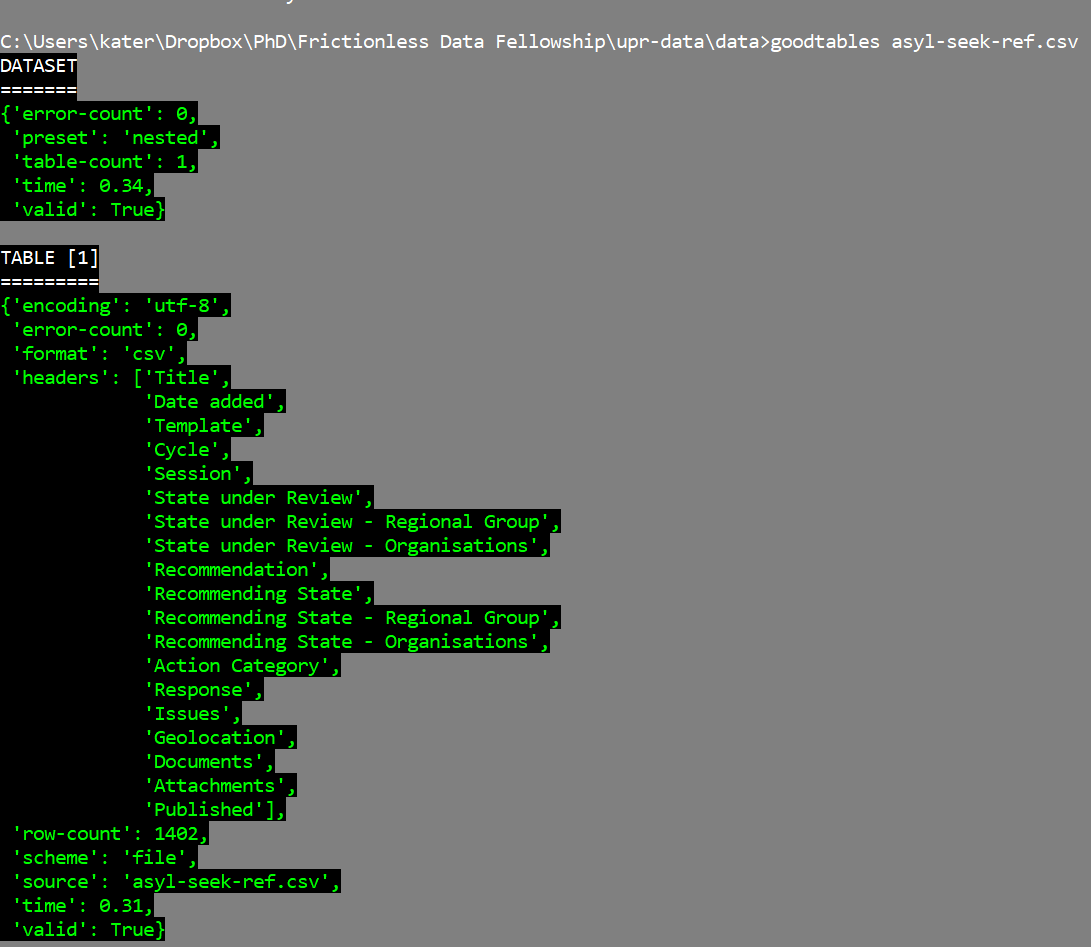
I can validate data files one by one .
But, then I realised that there's got to be a more efficient way to do this! I had to do a bit of googling to see what the frictionless framework could offer, and realised I could valildate my partner's whole datapackage! So, that's why it's useful to create datapackages!

I find it very interesting that even though I was introduced to some concepts quite early on in the fellowship, my understanding of them changes and becomes more deep with time.
So if I type this, frictionless will validate all packages for me:
frictionless validate *.csv
However, this results in a very long list, where some files are valid, whereas other are invalid. An example of a valid file:
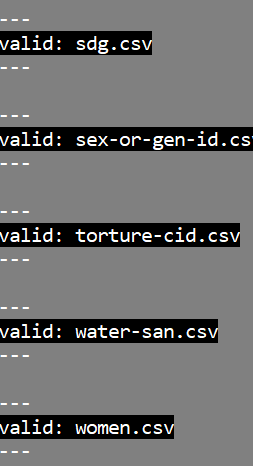
Some of the files that were valid .
An example of an invalid file:
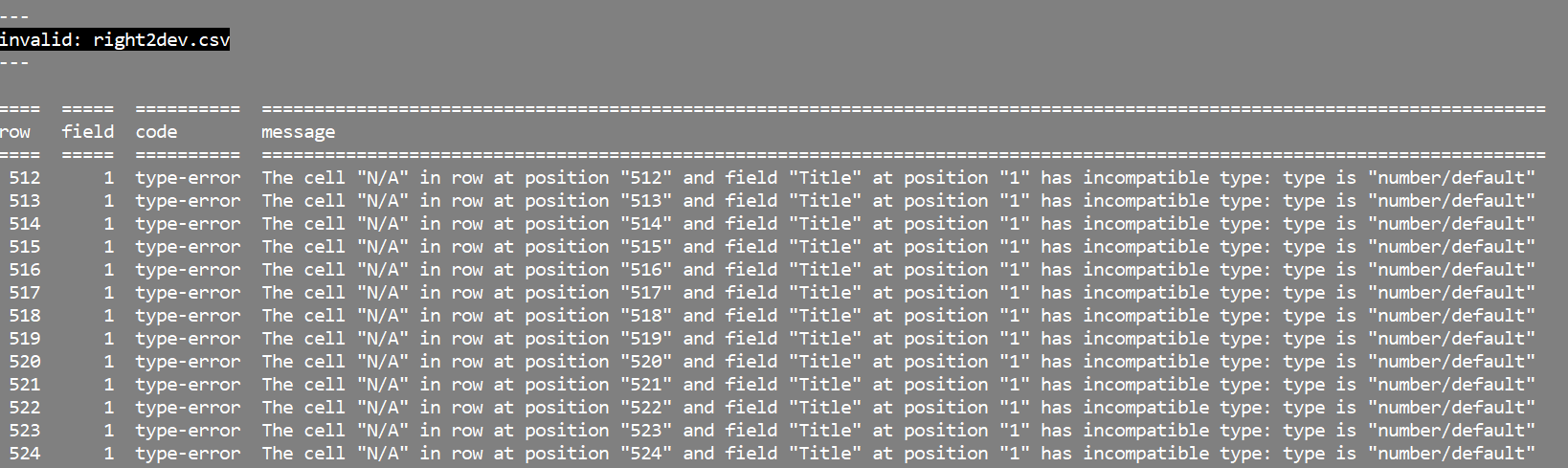
Some of the files that were invalid .
Indeed, when going back to the file, instead of a numeric value, there is N/A. With such large files, it is a good thing that this came up using the frictionless tool, as I don't think that it would be possible to detect this with the human eye across all files. I had discussions with my partner about the invalid files, and she said that this is how the files were made available to the public, and that indeed, no information is available for the specific rows in the specific columns. This is an issue that needs to be communicated to the organization that has released the data (the UN in this case), and probably needs to be clarified in their meta-data.
Conclusions
In this task, I've had to take someone else's data from their github repository, understand what the data are about, and do simple validation checks using goodtables. Understanding the material, although it needed some attention, did not prove very difficult. Validating the data (to the extent that it was possible after all) was easy using the goodtables tools. Another take-home message is the fact that I seem to understand more deeply many of the terms I've been introduced to earlier in the fellowship and that I understand in practical terms why some things are best to be done/presented in a specific way.