Lindsay Datapackage Blog
Introduction
The first tenet of the American Library Association’s Bill of Rights states: “Books and other library resources should be provided for the interest, information, and enlightenment of all people of the community the library serves” (American Library Association). Libraries are supposed to be for everyone. Unfortunately, like many other institutions, libraries were founded upon outdated and racist patriarchal heteronormative ideals that ostracise users from marginalized backgrounds. Most academic libraries in the United States use the Library of Congress Classification System to organize books, a system that inadvertently centers christian, heterosexual white males. Critical librarianship, or critical cataloging is “a movement of library workers dedicated to bringing social justice principles into our work in libraries” critlib. I would like to use data science principles to explore bias in library MARC (machine readable catalog) records.
The Data
First, I needed to find MARC records to use. I searched the HathiTrust Digital Library for a public dataset so that my workflow would be as reproducible as possible. Unfortunately, Hathifiles do not include several of the fields I would like to explore. I know bias exists in Library of Congress Subject Headings (LCSH), which is field 650 in a MARC record. I would also like to explore the 500 field (General note) and the 505 field (Formatted contents note - often a table of contents). I reached out to colleagues to download MARC records for me. I asked for anything in our collection that resulted from a keyword search of “basketball.” The LCSH “Basketball players” is problematic in nature. LCSH are organized hierarchically. Narrower terms (hierarchically lower) for "Basketball players" include “Basketball players with disabilities,” “Indian basketball players,” “Jewish basketball players,” and “Women basketball players” while there are no terms for “able-bodied basketball players” or “white basketball players.” This illustrates the bias that a traditional basketball player is an able-bodied man.
Data Package Creation
I received the MARC records in a variety of formats, including. json, .txt, .mrc, and .mrk. The data needed to be in tabular (csv) form for the Frictionless Data Package Creator. Unfortunately, when converted, the txt file puts all of the data into one column. After some trial and error and Internet searching, I found a helpful YouTube video, Converting a MARC file to Excel with MarcEdit. I downloaded MarcEdit 7.5, selected the MARC fields I wanted, and voila! I had a tabular MARC dataset.
One the data were in a tabular format, using the Data Package Creator was simple. I uploaded the data, selected data types, named my fields, validated my data, and downloaded my .json data dictionary. I had some issues with null fields, and had to reopen my dataset and add “n/a” into all blank cells in order to identify the Data Type for each column in my dataset. After that, validation was a breeze. Since my dataset was machine readable prior to using the Data Package Creator, I had no red flags during validation.
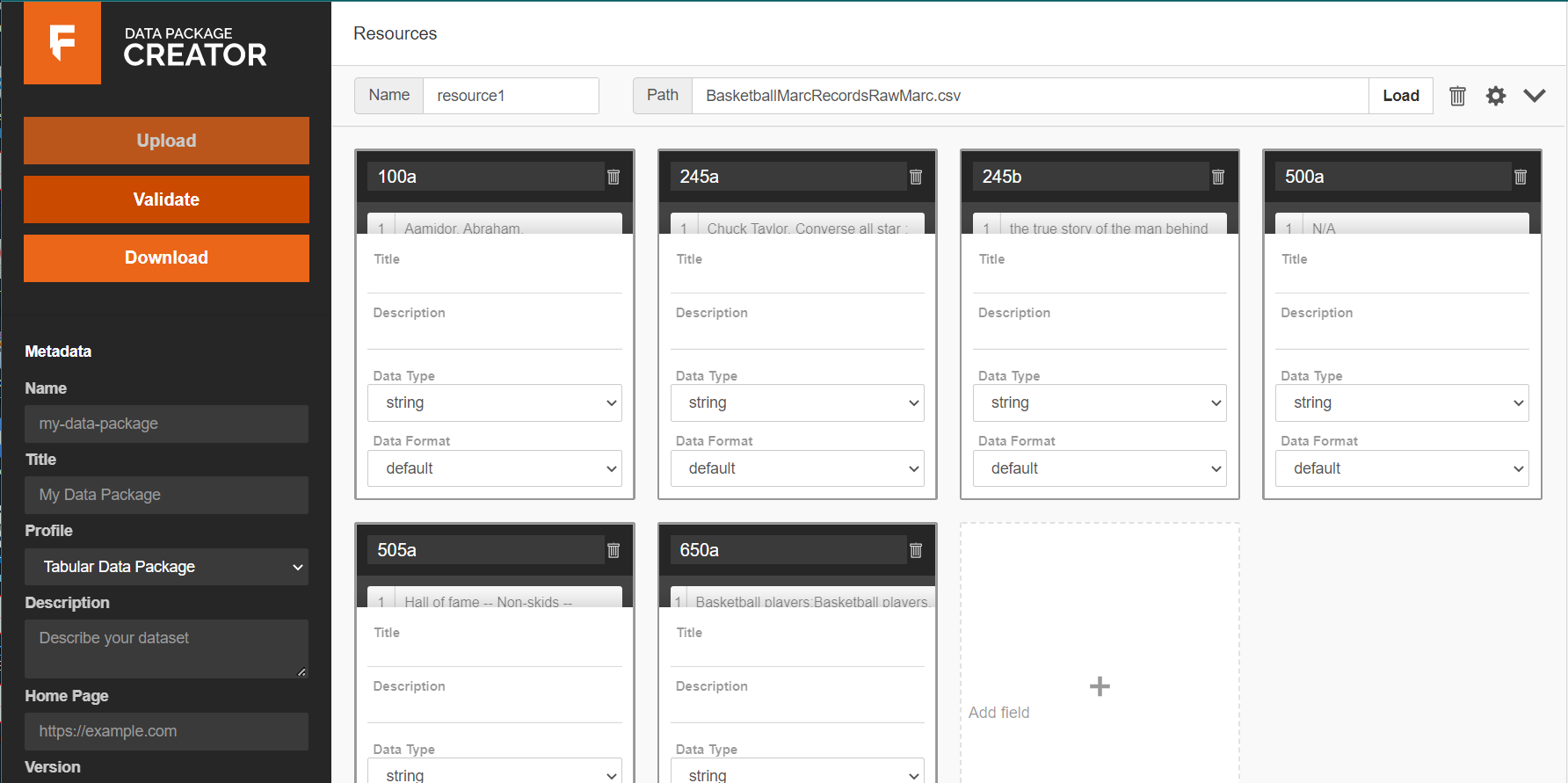
A screenshot of the data package creator.
Conclusion
The Data Package Creator is a useful tool for creating a machine readable data dictionary for tabular data. Although my dataset was already in a machine readable format, using the Data Package Creator with MarchEdit 7.5 helped me to whittle a massive dataset of MARC records into a manageable dataset with just the bits of MARC record I need to explore systemic bias. Also, JSON is kinda pretty.
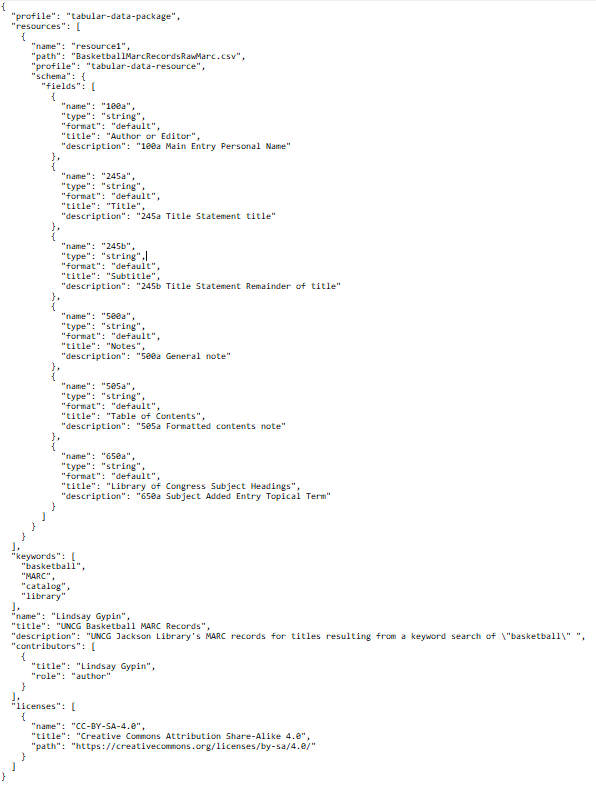
A screenshot of the resulting JSON file.