Trading Data Packages for Reproducibility
Introduction
We had an interesting task for our frictionless fellow activity that involved exchanging our data sets with our fellow colleagues (pairwise) and trying to reproduce their work. My partner for this assignment was Lindsay, who is a librarian. More information about Lindsay can be found here.
In data science, replicability and reproducibility are some of the keys to data integrity.It creates more opportunities for new insights and reduces errors. In order to ensure reproducibility of data, one must first make sure that the raw data is available. In this regard, my partner Lindsay shared with me her data that was on her Github account to facilitate the process.
This process and activity were really useful and humbling. As we got to discuss our data sets with Lindsay, I realized key things such as Tidy data principles, which was the highlight for me in this whole process, besides the point that it's not easy to understand someone else's data without further metadata to accompany the data set. Imagine the frustration researchers go through trying to understand and reproduce other people's data without more information on the data. Follow through to see how I managed to reproduce my fellows' data package.
Getting the data
Once I received the github link to the data, I was able to locate the data. However, the data was really huge, and for the sake of making the process not so cumbersome, Lindsay shared a subset of the data with me. Lindsay and I are in different fields, so this whole process was interesting to get to learn and understand what we do through our data. She is passionate about bringing social justice principles to libraries. The data was to be used to explore bias in library MARC (machine readable catalog) records. The metadata contained the author name, title of the book, sub-title, book description, table of content, etc.
Once I had the sub-set data, the rest of the process was pretty simple. I used browser tools to create the data package and run the validation process. I keyed the link and loaded it into the data package creator, entered the metadata, and pushed the validate button. The data package came out valid as shown below.
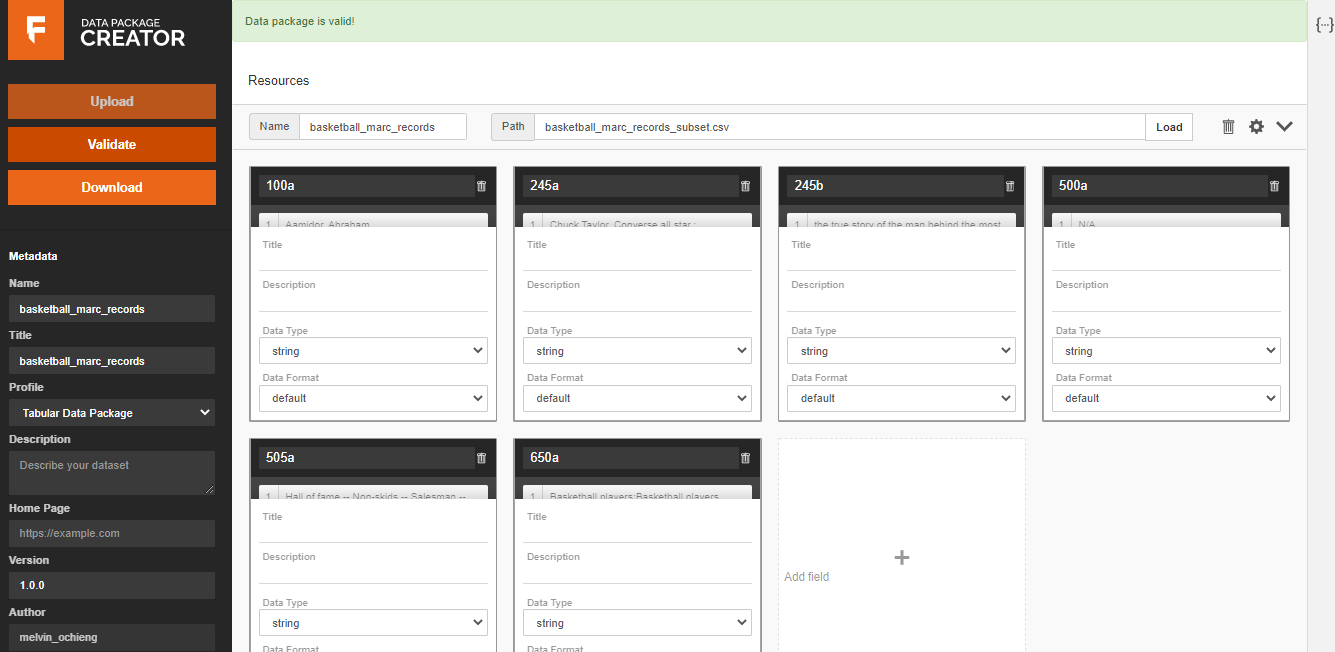
Once that was done, I then ran the data using Goodtables to validate the data and the data came out valid as shown below.
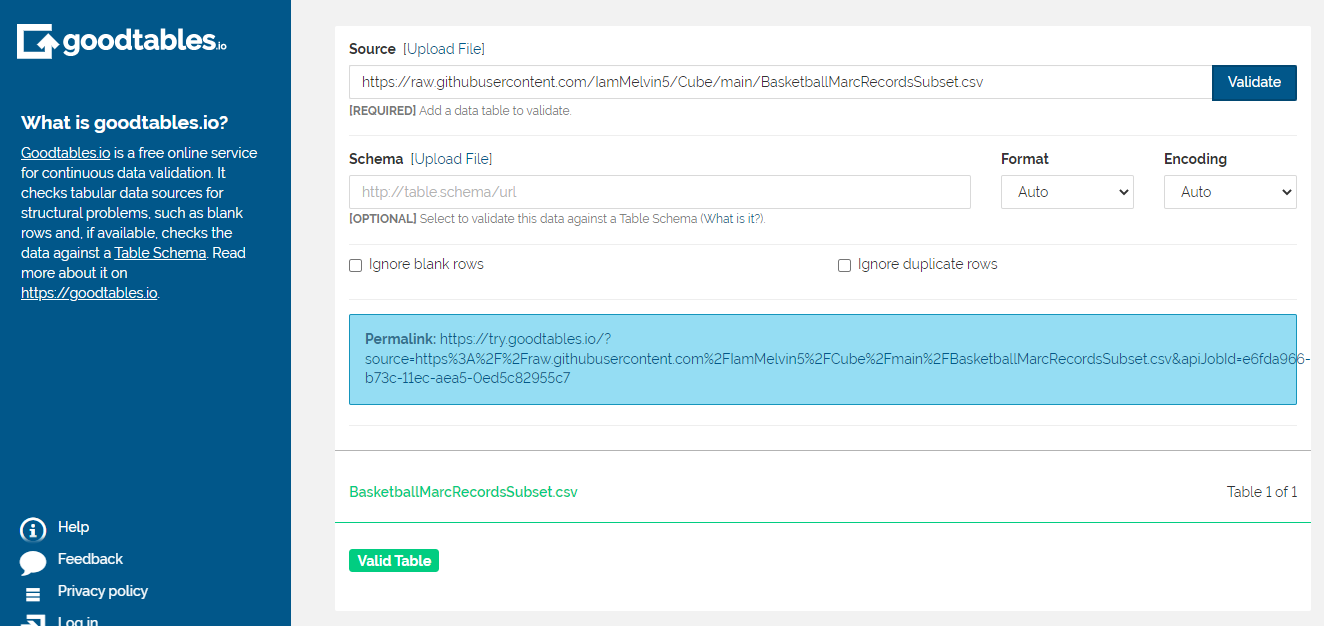
With these steps, I was able to reproduce Lindsay's data.