Using Weather and Rainfall Data to Validate
I am using a data resource from Telangana Open Data and hence the delay in uploading this! It is an open source data repository commissioned by the state government here in India and basically it archives and stores Weather, Topological, Agriculture and Infrastructure data which then can be used by research students and stakeholders keen to study and make reports in it. The lab where I work helps the data servers up and running and helps upload the data and also uses the uploaded data as it allows people to independently upload their data after verifying it so that researchers can use it.
The data that I am using today is sourced from monthly weather data website and I am not using github in order to get the data but I will link the data repository here:
https://data.telangana.gov.in/search/type/dataset?query=weather&sort_by=title&sort_order=ASC
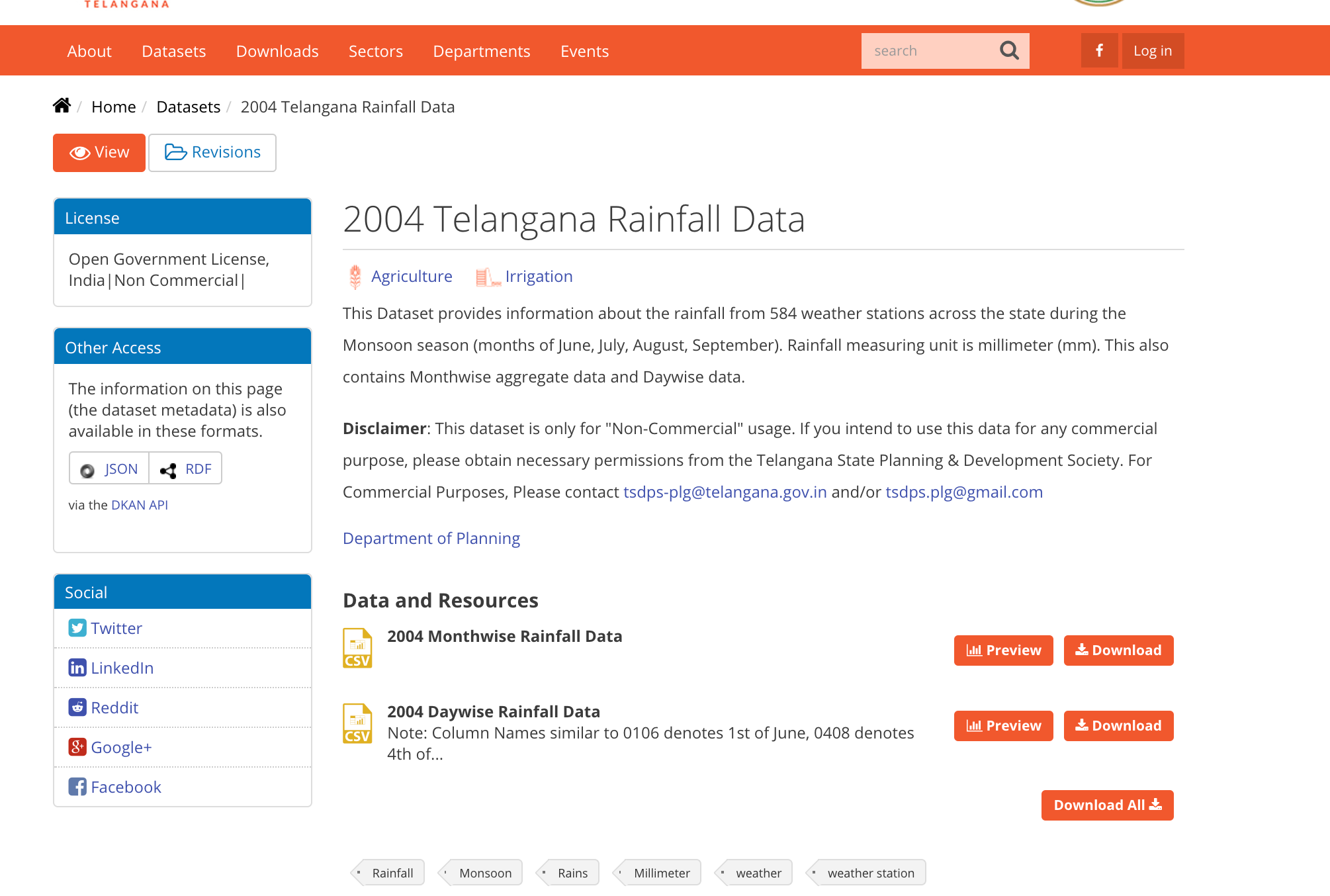
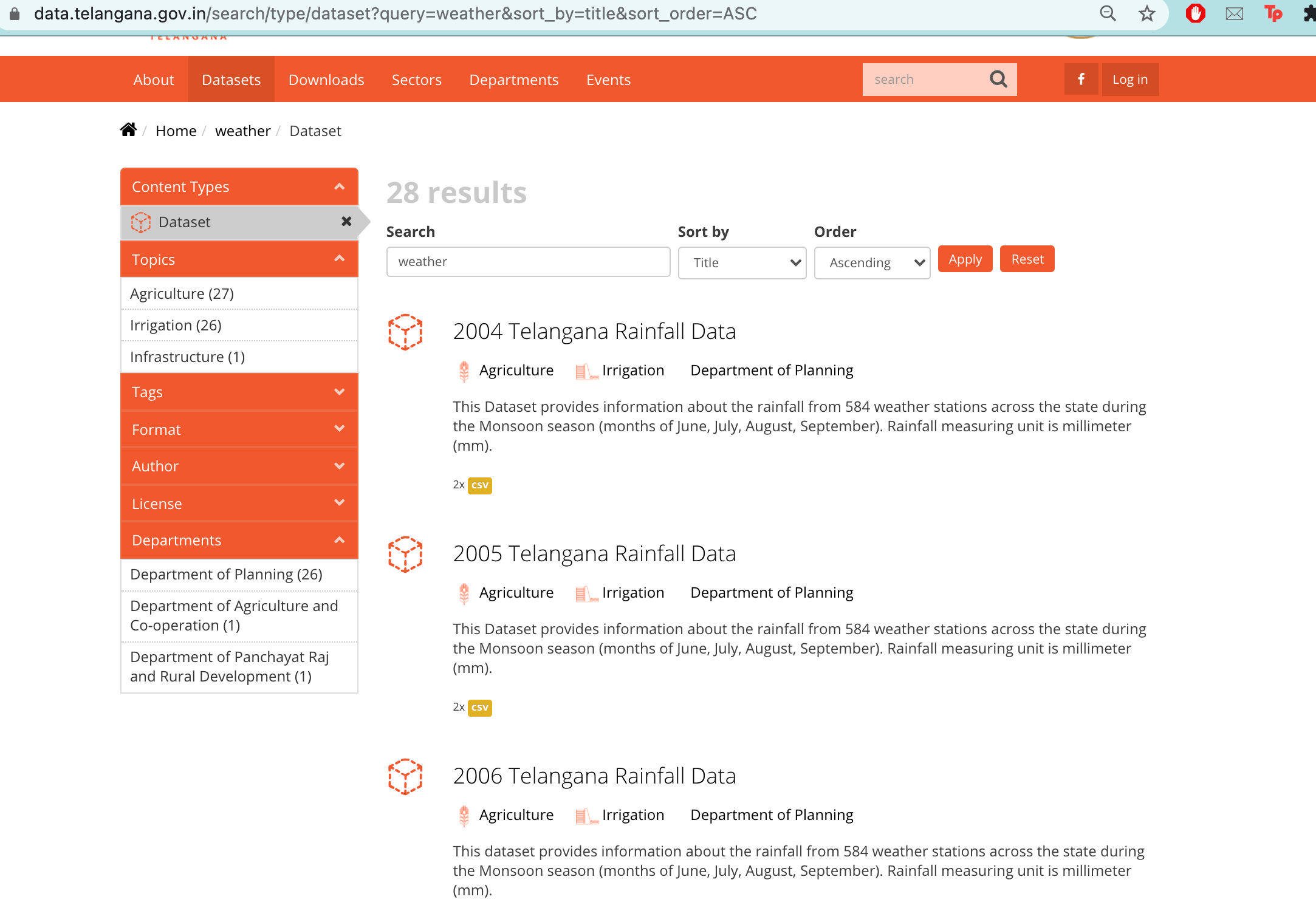 You can basically categorise the data and filter it based on different names and titles and after getting results you can either download the csv file or can see the preprint of the data on the website itself for you to see.CSV files are very versatile, but cannot handle the metadata with all the necessary context. We need to make sure that people can find our data and the information they need to understand our data. That's where the Data Package comes in!
You can basically categorise the data and filter it based on different names and titles and after getting results you can either download the csv file or can see the preprint of the data on the website itself for you to see.CSV files are very versatile, but cannot handle the metadata with all the necessary context. We need to make sure that people can find our data and the information they need to understand our data. That's where the Data Package comes in!
Creating and Using a Data Package
To do this, we will be using the Data Package Creator. Although we can create a Data Package through the command-line tools, we will use the browser tool for simplicity.
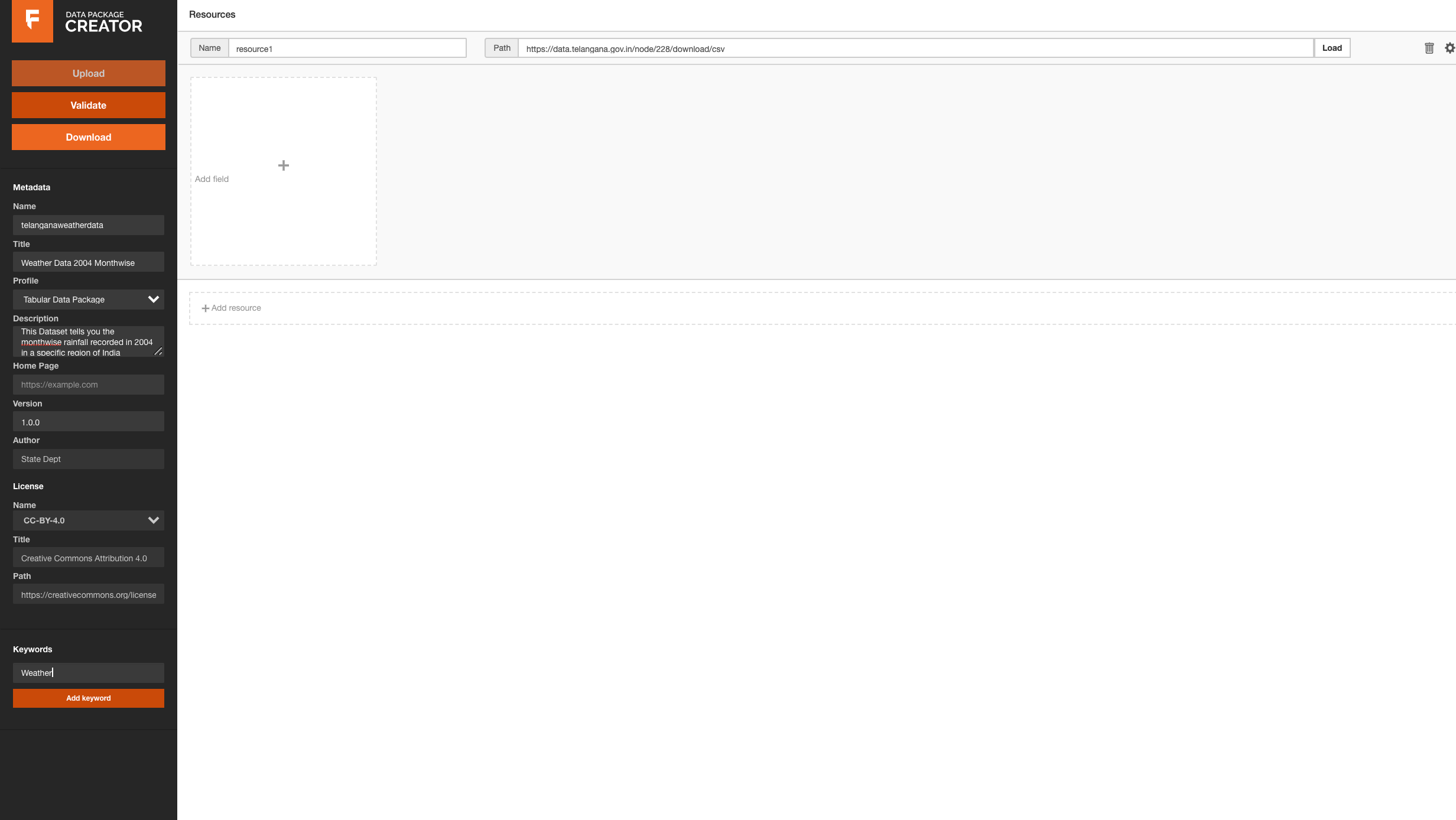
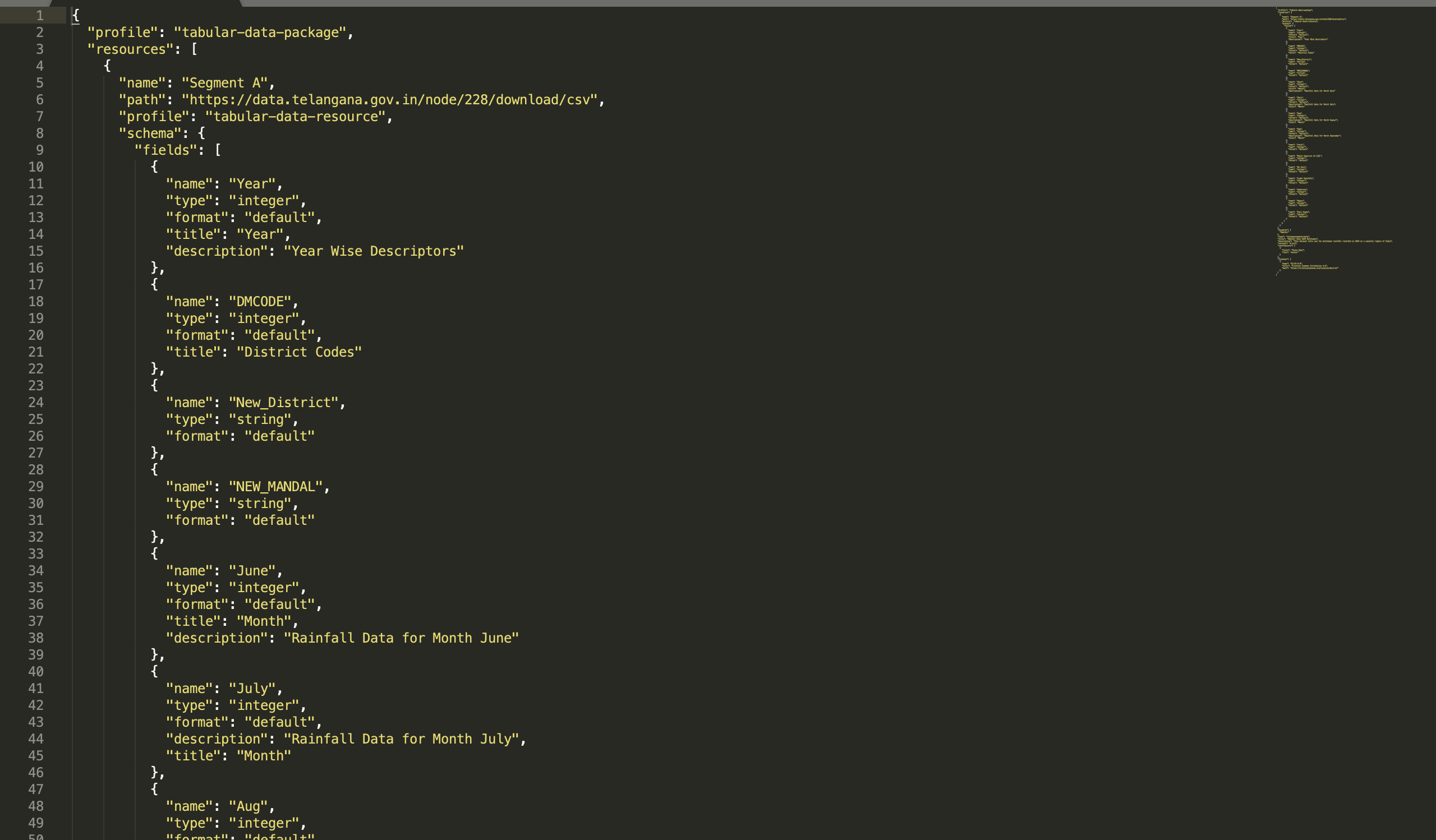
- We are going to give a (machine read) name and a (human read) title to our Data Package;
- Then we will add a description, so people know this data comes from a open source website and they can use it later on
- We can also add a version number to the Data Package. This is particularly interesting if you assume you will be updating the data resources in the future, for example during data collection.
- We will add a license. Without a license, people cannot know whether they are allowed to use your data. Here you will find a list of possible licenses that you can use, but also you can add any other license. If you want to read more about each license, selecting one will generate a link to the Creative Commons website where you can read about the details of that license.
- Finally, we will add as many relevant keywords as we can, as this will make out data more findable
Adding the Data links and/or uploading the files
At the top of the panel, we will see that we can add the name and path to a data resource. The best option for us is to use the link to the data we can get from the csv file on the website, rather than uploading the data again from our computer. This way, other people will be able to find our data through that link as long as they have access to the Data Package metadata.
After we load the path to the data from the resource, the Data Package Creator will automatically infer some of the characteristics of our data. First, it will show us how many columns it found, so that we can choose whether we want to import them all or just a subset. Then you will notice that it also inferred the header and data type of each column. Make sure the latter is correct, since this will be important for the validation of our data.
Adding more data we will let the Data Package Creator infer the metadata and we will simply check and correct any mistake:

The final Output
We're ready to hit the Validate button and see whether everything looks good. If the Data Package Creator finds any problem with your data or metadata, it will tell you what it is so you can easily fix it.Once we're done, we hit the Download button, which will give us a JSON file. This file has all the metadata that we introduced in a machine-readable format. This will allow anyone to read out our metadata using any tool they want. So now we have our JSON file ready for us to see :) .