Reproducing Jacqueline's Datapackage and Revalidating her Data!
Introduction
Our most recent fellowship task was to recreate our partner's datapackages using the Frictionless Data Package Creator, and then use Goodtables.io to validate their data. I was paired with Jacqueline Maasch, who I encourage you to read more about via her introductory blog!
The Data
Jacqueline shared her two blog posts with me outlining her process of creating a datapackage for her data and then validating her data. Via her blogposts, I found my way to her GitHub repository and located her dataset, "merops_peptidase_families.csv". Once I located the dataset, I took a look at it on GitHub and noticed it contained information about specific peptidase enzymes. In order to use her dataset straight from GitHub, I clicked on the button at the top of the dataset titled, "Raw" in order to generate a URL that could be used with the web version of both Datapackage Creator and Goodtables.
Data Package Reproduction
With the Raw URL for Jacqueline's data in hand, I navigated to the Frictionless Data Package Creator linked above and pasted the URL into the Path text box at the top of the screen. Once I loaded the dataset, five inferred fields were found. All of them had the appropriate data type listed, and all of them were labeled aside from field one, which did not have a header title on github. I was able to label all the data and add a description for each one, and added metadata on the left hand side of the creator screen. After filling out all fields, I clicked "validate" and had a valid data package to download. I looked at the .JSON file created and compared it to Jacqueline's datapackage published on her GitHub repository. The only difference between our two data packages was that she named the first field "Index" while I left it as "field1" since it was unlabeled.
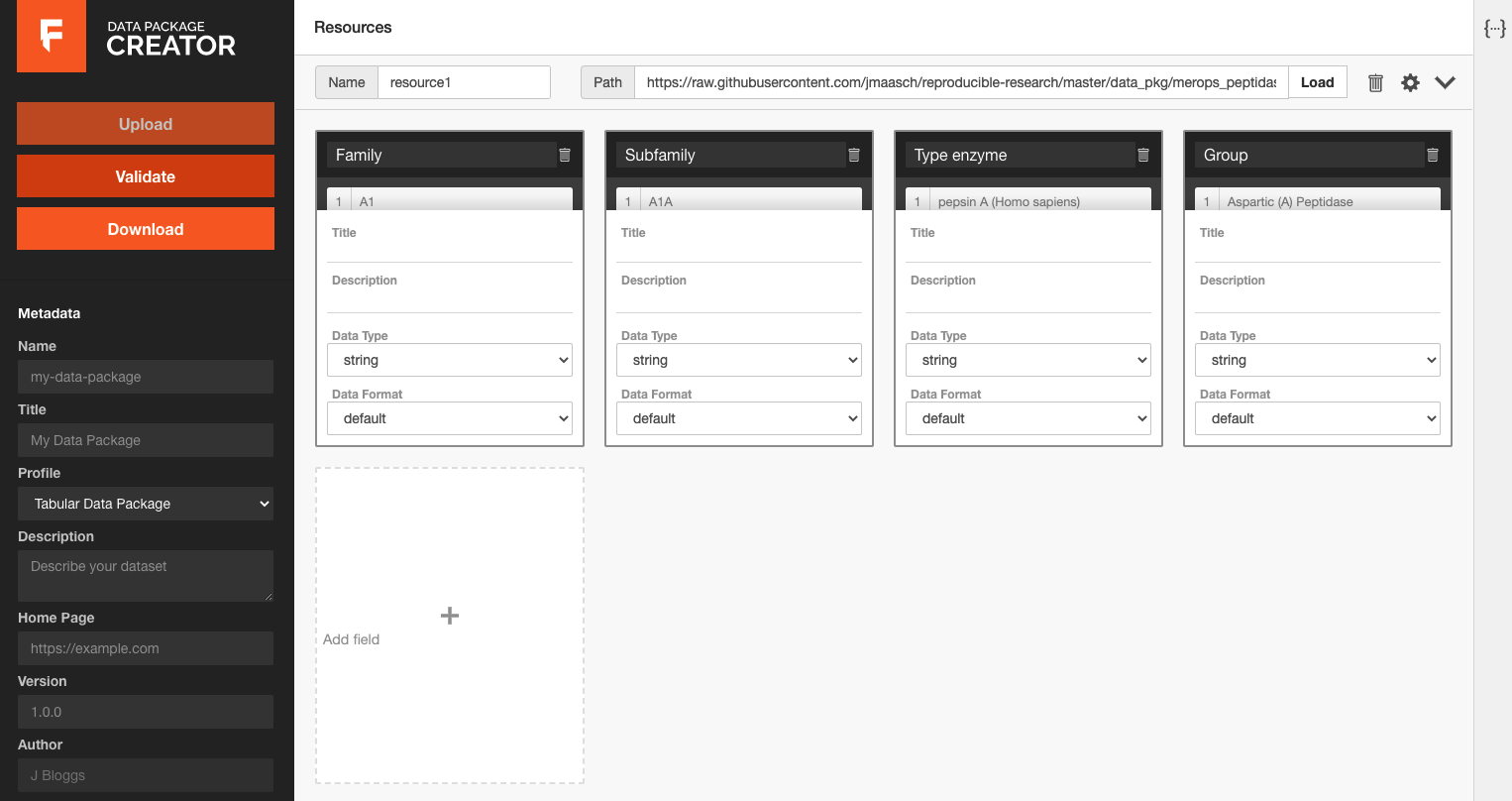
A screenshot of the data package creator after the URL for Jacqueline's data was loaded.
Data Validation
After successfully reproducing Jacqueline's data package, I headed over to Goodtables to validate her data. I used the same URL and pasted it into the "source" text box at the top of the goodtables web interface screen. I then clicked "validate" because I did not have a schema to upload. At the bottom of the screen, one error was indicated, which you can see in the below screenshot. The Goodtables data validator recognized that there was one blank header present in the dataset which was not a surprise to me. The first field which Jacqueline labeled as "Index" in her datapackage was listed as "Blank Header" according to Goodtables. Aside from this missing header, there were no other issues with the dataset!
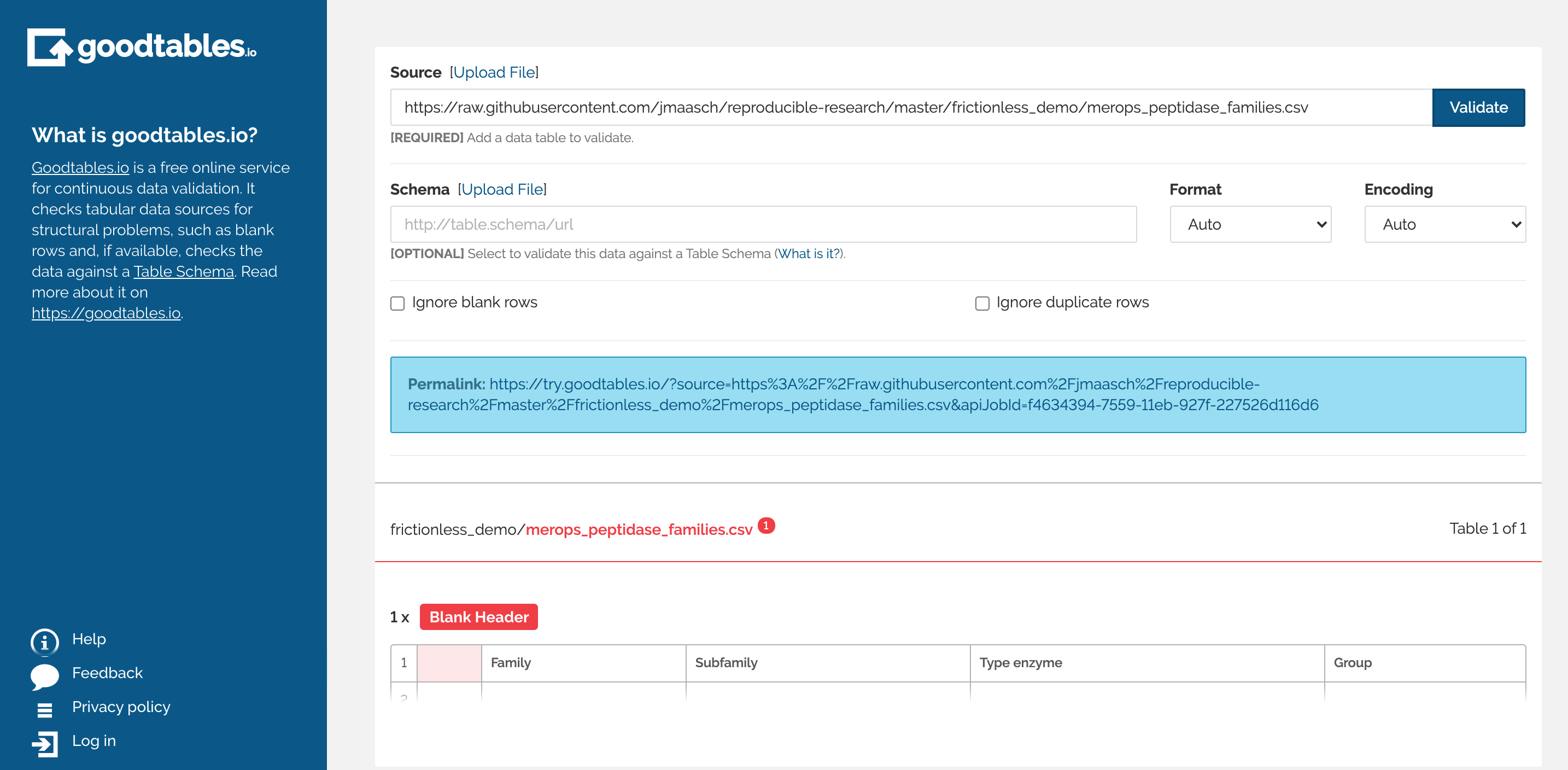
A screenshot of the GoodTables data validation results for Jacqueline's dataset. Note the missing header in column one.
Takeaways
Using Jacqueline's GitHub repository, Frictionless Data Package Creator, and Goodtables, I feel that I can confidently reuse her dataset for my own research purposes. While there was one piece of metadata missing from her dataset, her publicly published datapackage .JSON file on her repository helped me to quickly figure out how to interpret the unlabeled column. I also feel confident that the data is valid because after doing a visual scan of the dataset, I used the Goodtables tool to double check that the data was valid! Jacqueline's publicly available dataset is definitely findable, accessible, interoperable, and reproducible! Thanks for letting me use your data to attempt Frictionless Data best practices, Jacqueline!