Creating Data Package
As a social science researcher studying the research landscape in Central Asian countries, I decided to share a part of my dataset with key bibliometric information about the journal articles published by Kyrgyzstani authors between 1991-2021. The data I am going to share comes from the Lens platform. To ensure the data quality, and to comply with the FAIR principles, before sharing my data, I created a data package that consists of the cleaned raw data, metadata, and schema.
I tested two methods to create such a package. First, I tried to use the data package programming libraries. This method lets you do more than just to create a data package (e.g., describe, extract, transform, and validate your data). But I found the programming libraries a bit complicated. So, I ended up using the second method, that is the browser tool Frictionless Data Package Creator. It lets you create a data package without ay technical knowledge. The tool is comparatively simple and easy to navigate. It allows you to clean your dataset, change datatypes, provide a short description to your data as well as to add and edit associated metadata.
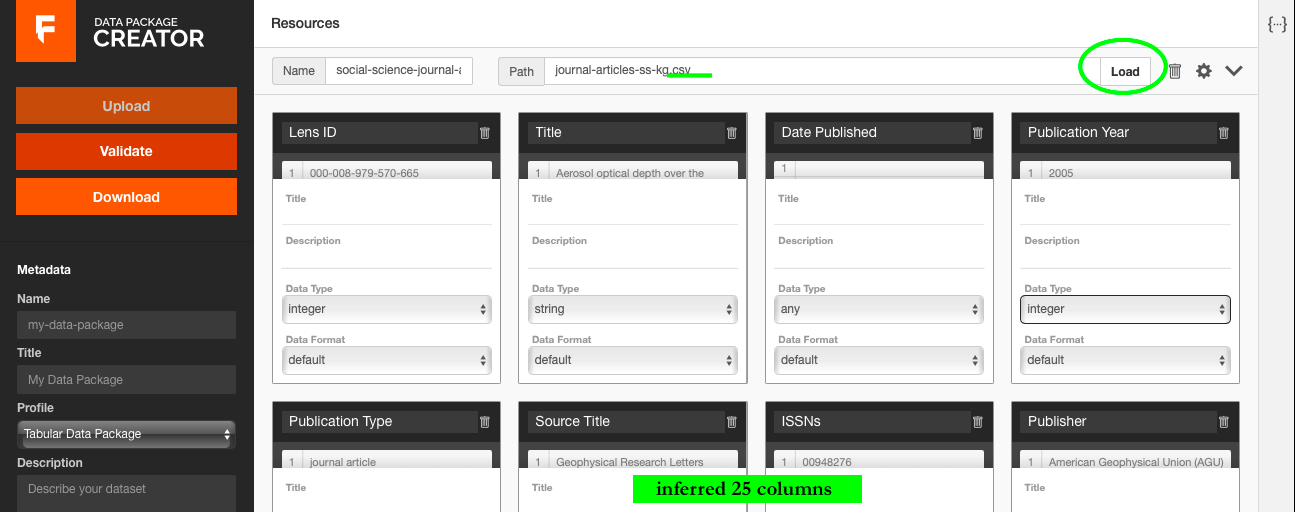
To start, I loaded my dataset path from my PC by clicking on the Load button. After several trials and errors with my excel file, I read the documentation and realised that the software works only with a CSV file. So, I converted my dataset to a CSV format and then re-uploaded it.
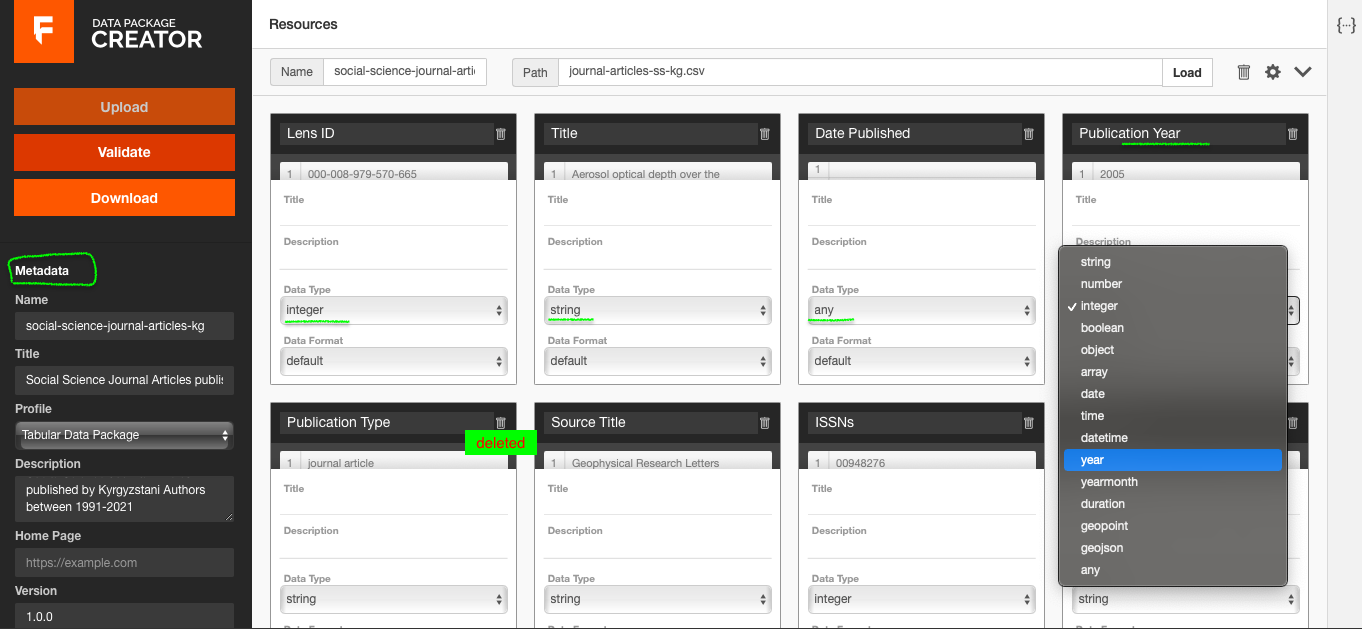
After I successfully loaded my dataset path, the tool automatically inferred the key characteristics of my data. First, it calculated and showed how many columns it found in the dataset. After I let the software import all the columns, it also inferred the header and datatype of each column. To make the data reusable, I gave a machine-readable name to my resource, deleted unnecessary and empty columns, and checked & corrected the data types of all the columns. After cleaning my data resource, I filled out the metadata for the package by providing a machine-readable name and a human-readable title, a short description of the data package, a version number, a required attribution, license information, and finally keywords.
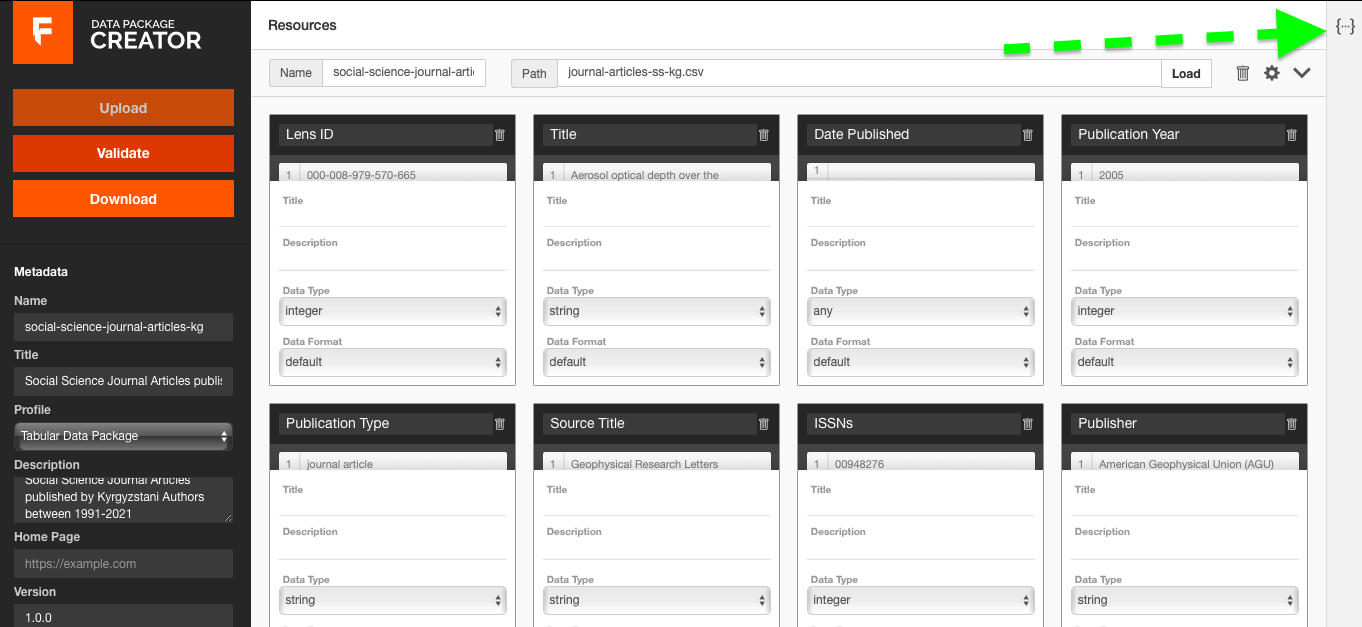
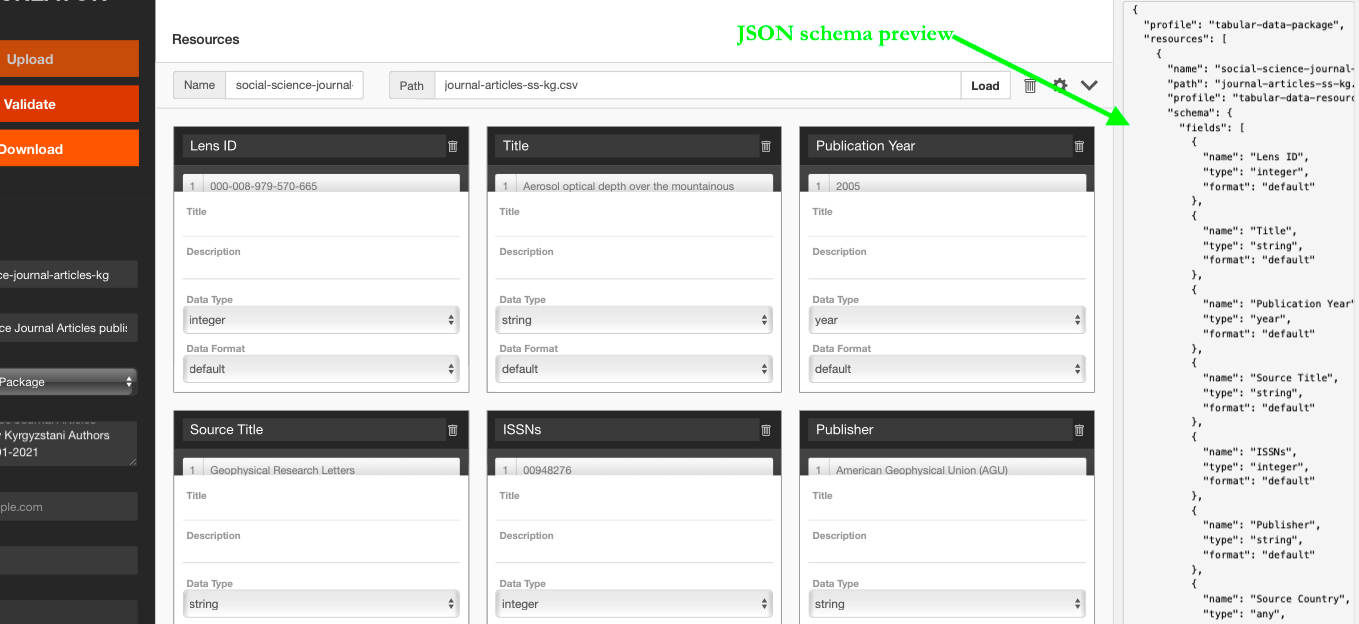
While you clean and fill out your metadata, the software automatically creates and updates a JSON schema file, which you can find by hitting the symbol {...} on the upper-right corner of the page.
After making sure that everything looks good, I clicked the Validate button. The Data Package Creator tool found no errors in my data and metadata, so it rendered a green-ribbon message saying the data package is valid. As a final step, I clicked the Download button and it gave me a single JSON file with all my data resources and associated metadata.
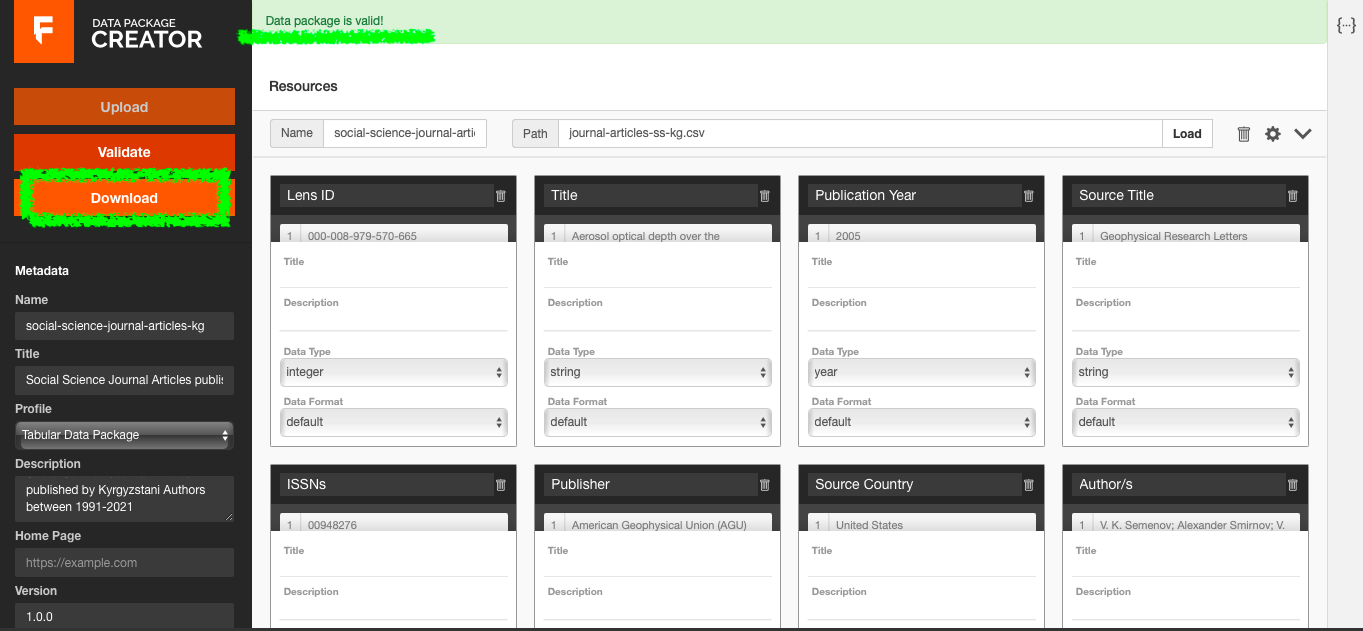
To sum up, I find a data package creator tool very useful for making your dataset clean, shareable, and of high quality with all the necessary contextual information. If you want to learn more about a data package specifications and how to create one for your datasets, you can read it here.