Validate tabular data using Goodtables tool
Goodtables is a free web tool that can help identify structural and content errors in tabular data (e.g., an Excel table). It can identify a wide variety of errors that can exist in a real dataset, including blank header name, duplicate rows, missing value, etc. A more exhaustive list of different types of errors is available here. In this blog, I am going to illustrate using Goodtables to validate tabular data (one-time data validation). For continuous data validation, please check out this blog.
Prepare dataset
The dataset ‘All-Cause Mortality.csv’ I am going to use is from a Data Package that I created in my last blog. In order to illustrate how Goodtables can identify different types of errors, I am going to manually introduce three common types of errors into the dataset: missing value, duplicate rows, and format error (e.g., the type of data does not match the type of variable). The modified dataset can be downloaded here.
Validate data without a schema
Step 1
Import dataset into Goodtables tool. As the dataset is on GitHub, I can directly copy and paste the raw code into the Source input.
Step 2
Validate the data. Goodtables will upload and validate the dataset automatically.
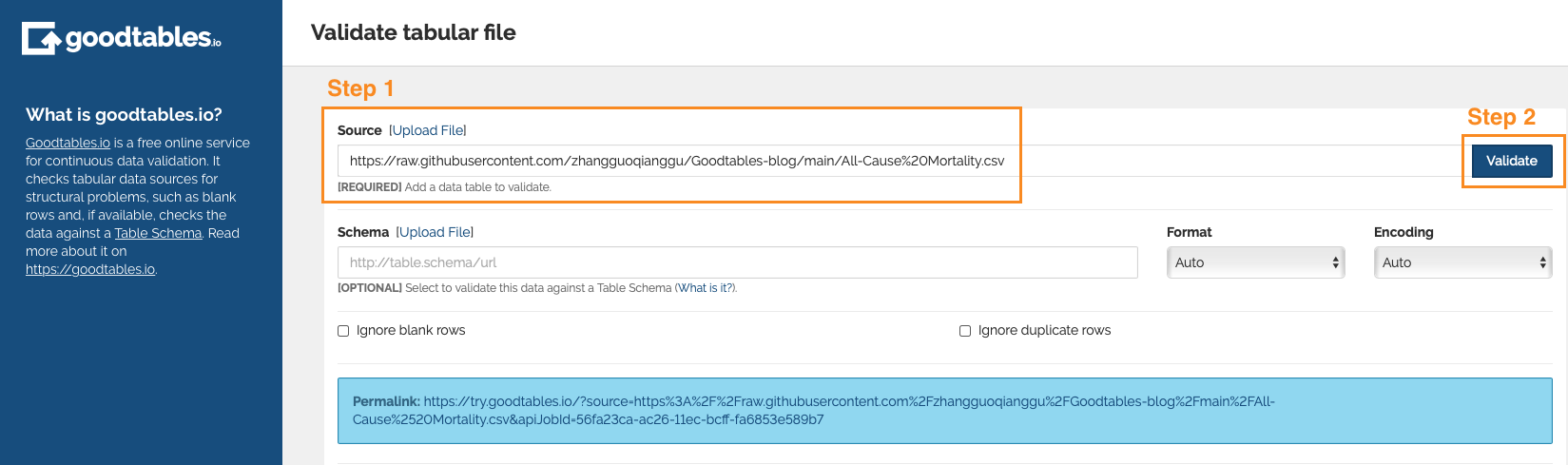
Step 3
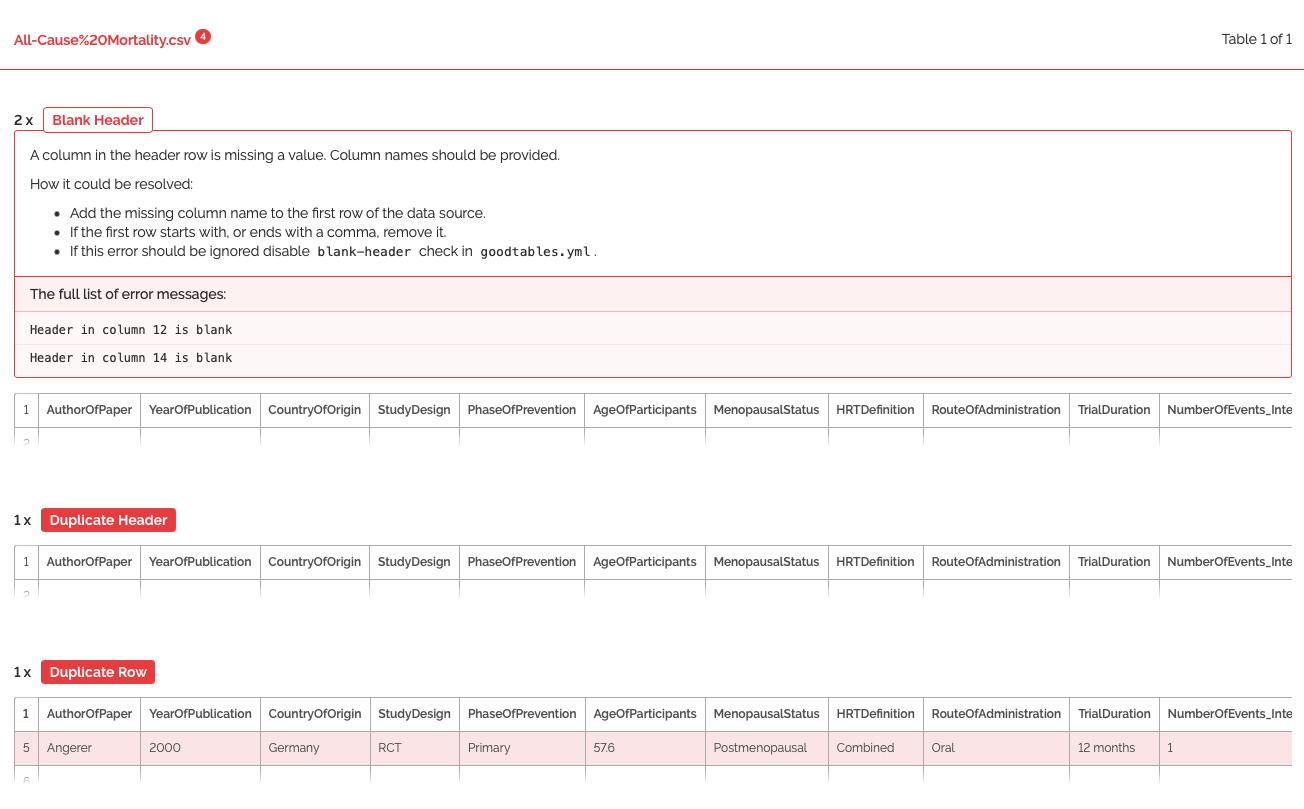
Check the validation report. As illustrated below, in the dataset, Goodtables finds out that there are two headers that are blank and one duplicate row. This report can be then used as a guide to manually fix these errors.
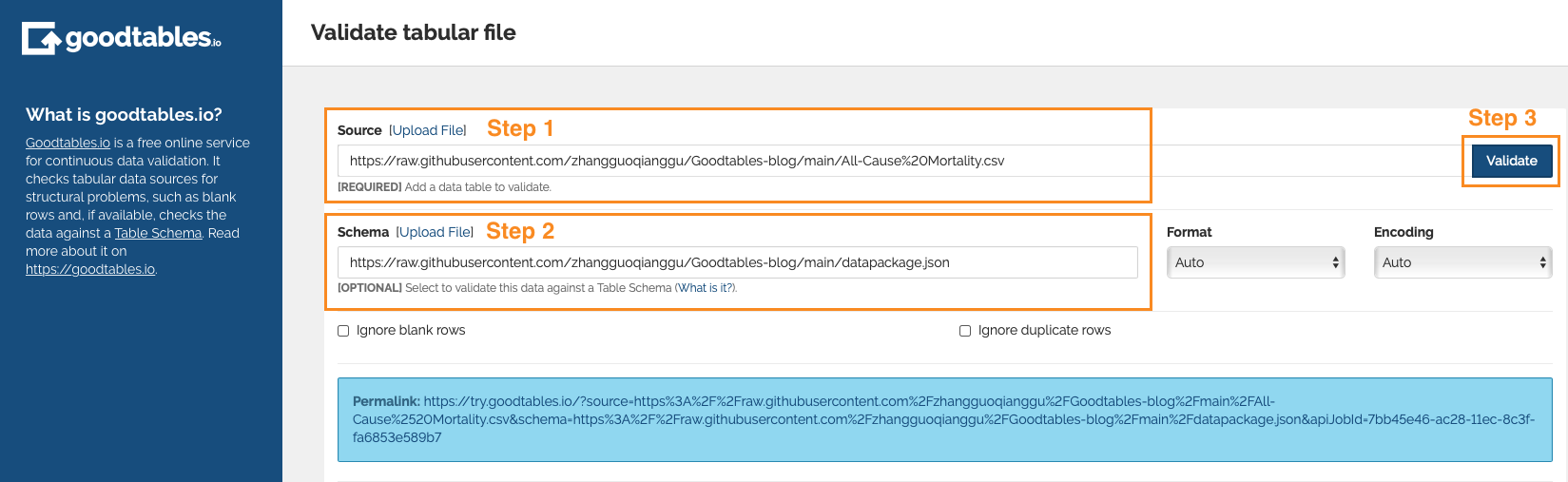
Validate data with a schema
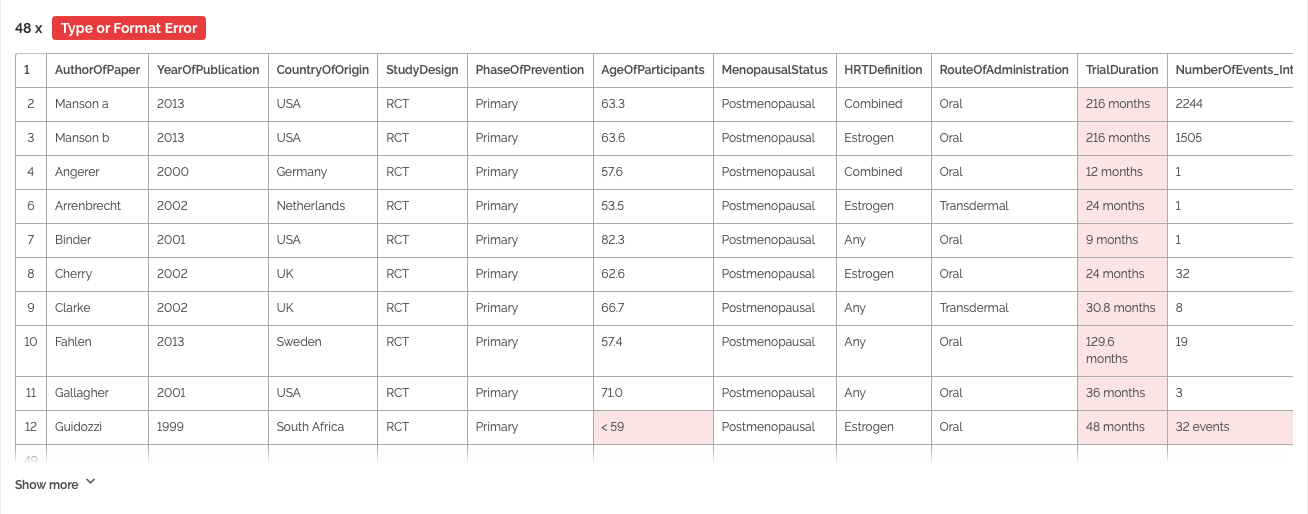
A data schema provides information about the structure of tabular data. If a data schema is supplied, Goodtables can also check for content errors (e.g., mismatch between data and type of variable). The data schema for ‘All-Cause Mortality.csv’ can be downloaded here. Following the steps illustrated below, Goodtables finds out that, in addition to the errors identified above, there are format errors in three variables: in the data schema, ‘AgeOfParticipants’ is number, and ‘TrialDuration’ and ‘NumberOfEvents_Intervention’ are integer, while in the dataset character exists in the three variables; therefore, the data are inconsistent with the types of variables specified in the data schema.