Trading data!
Happy families are all alike; every unhappy family is unhappy in its own way — Leo Tolstoy
Like families, tidy datasets are all alike but every messy dataset is messy in its own way. — Hadley Wickham, Chief Scientist at RStudio
Preach, Hadley! Within the scope of the Frictionless Fellowship, we’ve been learning about how to adopt good data practices to facilitate reproducible research. Speaking from personal experience, however, being in the weeds of data often makes it hard to objectively asses its interoperability. Sometimes this manifests as structural problems within the data, sometimes its more of human-readable speed-bump, like unexplained naming conventions, or obscure units.

Sure
Having prepped our own data using Frictionless tools, the idea was that we would trade data packages with a researcher from a different field, and navigate the experience of reproducing research, field agnostically.
My data package partner, Zarena is an awesome social scientist in the human rights sphere. She has a background in mental health research and interests ranging from epistemic injustice to intersectionality - two terms I had to double check my understanding of. In poking around Zarena’s profile, particularly interesting was her focus on mad studies, a young interdisciplinary field dealing with identity and the marginalisation of individuals with alternative mental states. This idea - broadly accepting a spectrum of human states instead of subjecting them to a black/white absolute interpretation - was completely new to me and fascinating! But being a social theory noob, I suspected to encounter a barrier to understanding her data.
Zarena’s data was publicly available in her GitHub fellows repository. I clocked a couple of things off the bat: the repo contained a csv called “data-dp.csv”, as well as a README.md and several schema files. When in doubt of where to start, a good place to look is the README.
Zarena's fellows repo
README.md files are meant to serve as repo guides - containing information such as sources, usage instructions, necessary libraries etc. They’re there to preemptively answer questions users could have when happing across your repository for the first time.
Zarena’s fellows repository README looked (unfortunately) much like my own - welcoming, but admittedly completely uninformative. I had written mine without taking into account that someone might actually check it out and use the data, and my assumption was that Zarena had done the same. So I forged ahead and put on my data detective hat.

Raw data Rorschach test - what do you see? My eyes are drawn to “Cows have significantly higher heart girths
A cursory inspection of the data revealed it to be a massive literature review aggregate. First thought upon opening was - damn…. girl reads a lot. The csv also appeared structurally sound - clear headers, no obvious formatting fauxpas.
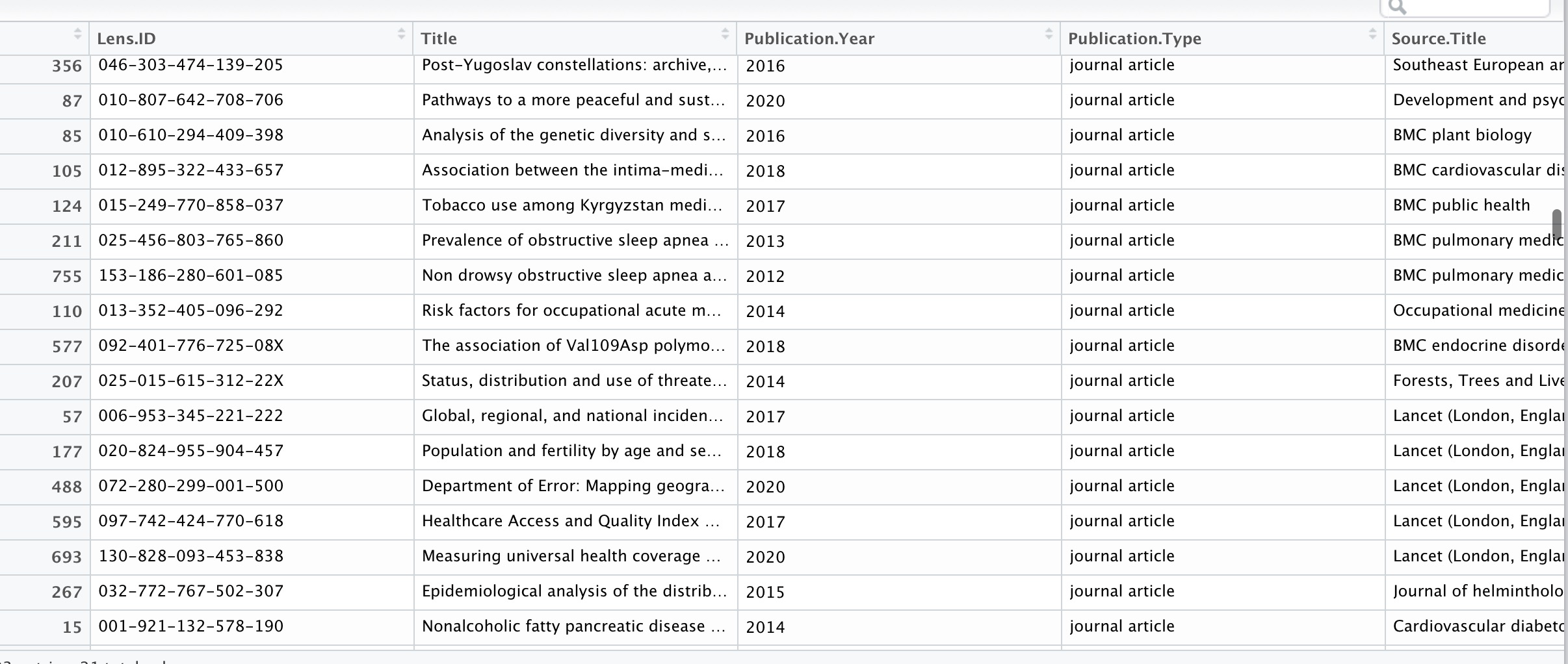
CSV for human eyes
However, though the fields were descriptive, (LensID might be the only column in need of some explaining), I still felt unable to understand and contextualise her data, and a more detailed investigation turned out more questions than answers. For example the title field contained a selection of top hits ranging from: “Thermal interaction between limestone and silica” to “Information dynamics in judo” to “Bride kidnapping in post-Soviet Eurasia: a roundtable discussion” to my personal favourite “Home-use cancer detecting band-aid” (yes I did look this up later and it is fascinating).
Similarly perplexing, the categories field touched upon every subject under the sun… horticulture, sleep apnea, corporate social responsibility, acne. It was as if I had entered the associative mind olympics, desperately searching for commonalities between “asymptotic expansion” and “hay.”

my own personal enigma code
At this point I thought - I should have really read more about what Zarena does. In her datapackage creation blog post she describes herself as a social science researcher studying the research landscape in Central Asian countries, and clearly states that her dataset is a bibliometric representation of publications from Kyrgyzstani authors between 1991-2021, coming from the LENS platform. Super clearly written and descriptive, this would make a great background section for a README file!
Finally understanding the nature of the dataset, I moved on to validation, using the frictionless command line tools. The datapackage - in this case composed of the csv and its schema - passed the test - valid! It’s always worth taking a slightly closer look however, as its easy to make mistakes at some point in the data cleaning and packaging processes. Trying to validate the csv alone produced the following error:
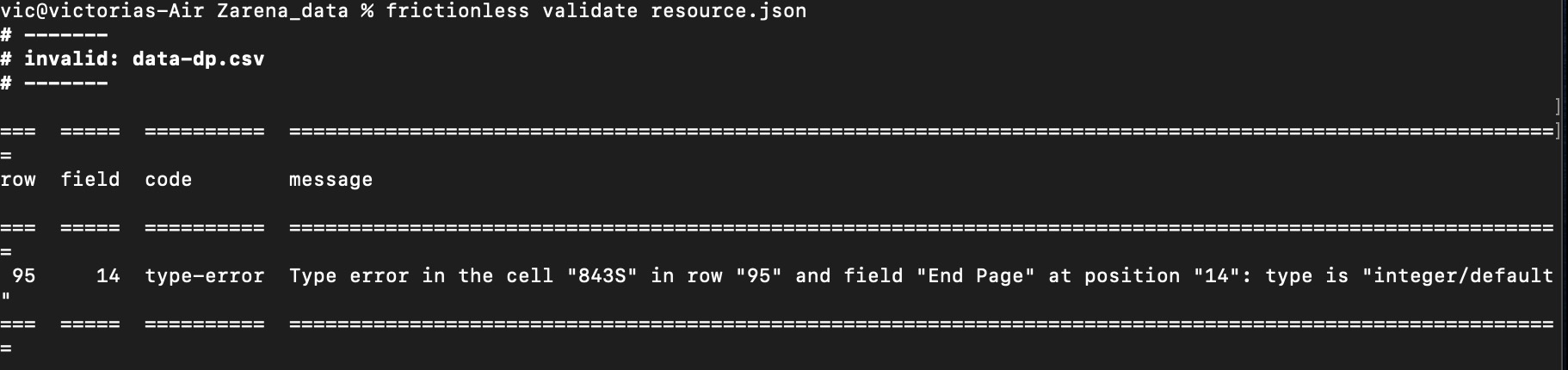
The error code clearly indicated the location of the error, which revealed itself to be a lingering letter trying to pass itself off as an integer. Not on my watch!
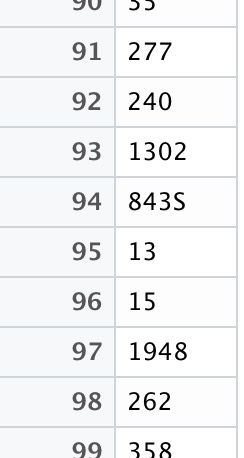
now I wonder if Zarena planted this here for me on purpose…
Did a quick little manual fix and we were on our way. As I got to the end of this exercise, I wondered: how interoperable was my own dataset? :O
A couple of good practices I hope to implement next time:
- Writing an instructive REAME
- Including a (permanent) link to the source data
- Instructive metadata, giving clear descriptions to variable names for example
- Cleaning your data according to Tidy data